To create the OLTP test schema based on the TPROC-C specification you will need to select which benchmark and database you wish to use by choosing select benchmark from under the Options menu or double-clicking on the chosen database under the benchmark tree-view. (For the currently selected database double left-click shows the benchmark options and double right-click expands the tree view). The initial settings are determined by the values in your XML configuration files. The following example shows the selection of SQL Server however the process is the same for all databases.
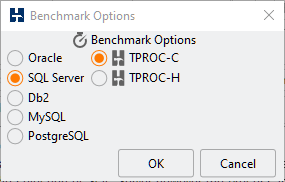
To create the TPROC-C schema select the TPROC-C schema options menu tab from the benchmark tree-view or the options menu. This menu will change dynamically according to your chosen database.
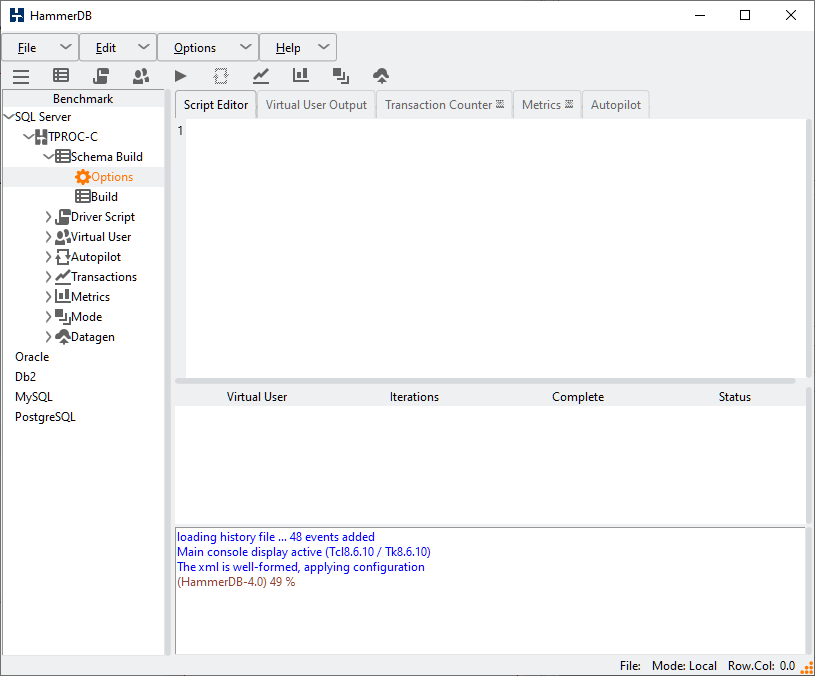
The “Build Options” section details the general login information and where the schema will be built and these are the only options of importance at this stage. Note that in any circumstance you do not have to rebuild the schema every time you change the “Driver Options”, once the schema has been built only the “Driver Options” may need to be modified. For the “Build Options” fill in the values according to the database where the schema will be built as follows.
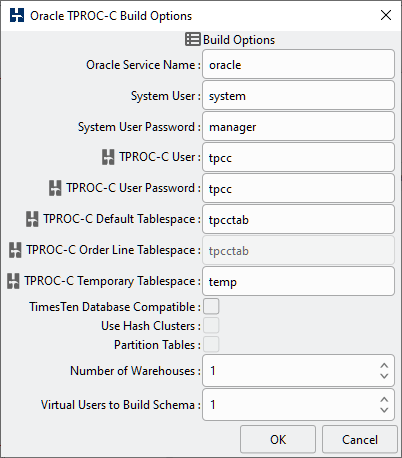
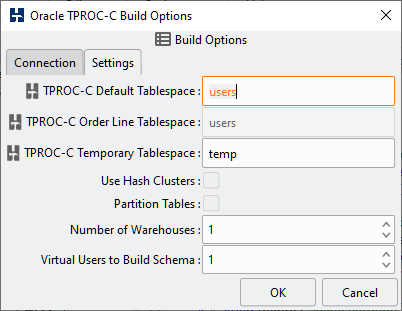
Table 4.1. Oracle Options
| Option | Description |
|---|---|
| Oracle Service Name | The Oracle Service Name is the service name that your load generation server will use to connect to the database running on the SUT database server. |
| System User | The “system” user or a user with system level privileges |
| System User Password | The system user password is the password for the “system” user you entered during database creation. The system user already exists in all Oracle databases and has the necessary permissions to create the TPROC-C user. |
| TPROC-C User | The TPROC-C user is the name of a user to be created that will own the TPROC-C schema. This user can have any name you choose but must not already exist and adhere to the standard rules for naming Oracle users. You may if you wish run the schema creation multiple times and have multiple TPROC-C schemas created with ownership under a different user you create each time. |
| TPROC-C User Password | The TPROC-C user password is the password to be used for the TPROC-C user you create and must adhere to the standard rules for Oracle user password. You will need to remember the TPROC-C user name and password for running the TPROC-C driver script after the schema is built. |
| TPROC-C Default Tablespace | The TPROC-C default tablespace is the tablespace that will be the default for the TPROC-C user and therefore the tablespace to be used for the schema creation. The tablespace must have sufficient free space for the schema to be created. |
| TPROC-C Order Line Tablespace | If the “Number of Warehouses” as described below is set to 200 or more then the “Partition Order Line Table” option becomes active. If this is selected then the option to select a different tablespace for the Order Line table only becomes active. For high performance schemas this gives the option of using both a separate tablespace and memory cache for the order line table with a different block size. Where a different cache and blocksize is used 16k is recommended. |
| TPROC-C Temporary Tablespace | The TPROC-C temporary tablespace is the temporary tablespace that already exists in the database to be used by the TPROC-C User. |
| TimesTen Database Compatible | When selected this option means that the Oracle Service Name should be a TimesTen Data Source Name and will grey out non-compatible options. |
| Use Hash Clusters | When Partitioning is selected this option enables the building of static tables as single table hash clusters and also disables table locks. These options can provide additional levels of scalability on high performance systems where contention is observed however will not provide significant performance gains on entry level systems. When Hash Clusters are enabled table locks are also disabled with the command "ALTER TABLE XXX DISABLE TABLE LOCK" and these locks will need to be re-enabled to drop the schema when required. |
| Partition Tables | When more than 200 warehouses are selected this option uses Oracle partitioning to divide the Order Line table into partitions of 100 warehouses each. Using partitioning enables scalability for high performance schemas and should be considered with using a separate tablespace for the Order Line table. Selecting this option also partitions the Orders and History tables. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally on this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |
The In-Memory OLTP implementation of HammerDB is intended to be as close as possible to the original on-disk HammerDB SQL Server Schema to enable comparisons between the two. The key areas for memory optimization are in-Memory optimized tables, the isolation level and the implementation of the stored procedures. Familiarity with the architecture of In-memory OLTP can benefit the understanding of the performance characteristics.
The key difference with the In-memory schema from the on-disk database is the organization of the tables. In-memory tables are implemented with hash indexes with no additional indexes created during the schema creation. Although the differences between hash and standard indexes are out of scope for this guide it is recommended to become familiar with the architecture as a key difference is the requirement to create all of the tables memory requirements ‘up-front’ with too little or too much memory impacting performance and therefore monitoring of the memory configuration usage is essential for workloads operating on In-memory databases. For a full implementation of in-memory tables a primary key is mandatory, however by definition the HISTORY table does not have a primary key. Therefore to implement all tables as in-memory an identity column has been added to the HISTORY table. It is important to note that despite the nomenclature of in-memory and on-disk databases in fact most of the workload of the on-disk database actually operates in-memory and high performance implementations can limit disk activity almost entirely to transaction logging in similarity to an in-memory database with persistence. Consequently orders of magnitude performance improvements should not be expected by moving to in-memory compared to a well optimised on-disk database.
During schema creation HammerDB sets the option MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT for the memory optimized database. As a result the use of the snapshot isolation mode is mandatory and this will be set without intervention of the user. For the on-disk schema the default isolation level of READ COMMITTED is used with the addition of hints within the stored procedures for specific statements.
In-memory OLTP introduces the concept of Native Compilation for stored procedures that access in-memory tables and the tables configured for HammerDB have been implemented with this in mind. However at current releases supported features of native compilation are highly restricted to the extent that it would not be possible to implement stored procedures in a native compilation form that would then provide a fair comparison with the on-disk schema. For this reason the same T-SQL stored procedures have been implemented with minor changes in areas such as removed hints locks and transaction isolation levels. Native compilation remains a consideration for future releases when the necessary features are supported to provide a fair comparison.
An in-memory database must reside in a memory optimized filegroup with one or more containers. This database must be pre-created before running the HammerDB schema creation. If the database does not exist HammerDB will report the following error:
Database imoltp must be pre-created in a MEMORY_OPTIMIZED_DATA filegroup and empty, to specify an In-Memory build
If the database exists but is not in a MEMORY_OPTIMIZED_FILEGROUP HammerDB will report the following error.
Database imoltp exists but is not in a MEMORY_OPTIMIZED_DATA filegroup
Therefore to create an in-memory database firstly create a standard database using SSMS or at the command line as follows:
use imoltp GO ALTER DATABASE imoltp ADD FILEGROUP imoltp_mod CONTAINS memory_optimized_data GO ALTER DATABASE imoltp ADD FILE (NAME='imoltp_mod', FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL13.SQLDEVELOP\MSSQL\data\imoltp_mod') TO FILEGROUP imoltp_mod GO
For SQL Server on Linux specify the filesystem as follows:
ALTER DATABASE imoltp ADD FILE (NAME='imoltp_mod', FILENAME='C:\var\opt\mssql\data\imoltp_mod') TO FILEGROUP imoltp_mod GO
Once the above statements have been run successfully the database is ready for an in-memory schema creation.
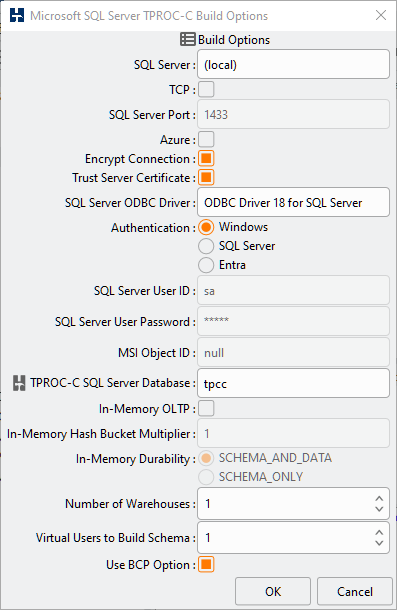
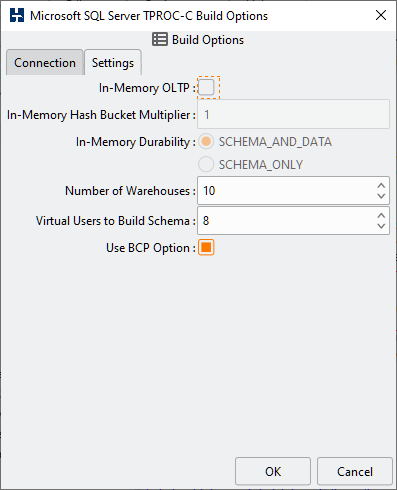
Table 4.2. SQL Server Build Options
| Option | Description |
|---|---|
| SQL Server | The Microsoft SQL Server is the host name or host name and instance that your load generation server will use to connect to the database running on the SUT database server. |
| TCP | Use the TCP Protocol |
| SQL Server Port | When TCP is enabled, the SQL Server Port is the network port that your load generation server will use to connect to the database running on the SUT database server. In most cases this will be the default port of 1433 and will not need to be changed. |
| Azure | Include the Database name in the connect string typical of Azure connections. To successfully build the schema this database must be created and empty. |
| Encrypt Connection | Provides the same functionality as the "Encrypt Connection" option in the SQL Server Management Studio connect dialog. This option is the default with ODBC Driver 18. |
| Trust Server Certificate | Provides the same functionality as the "Trust Server Certificate" option in the SQL Server Management Studio connect dialog. This option is the default with ODBC Driver 18. |
| SQL Server ODBC Driver | The Microsoft SQL ODBC Driver is the ODBC driver you will use to connect to the SQL Server database. To view which drivers are available on Windows view the ODBC Data Source Administrator Tool. |
| Authentication | When installing SQL Server on Windows you will have configured SQL Server for Windows or Windows and SQL Server Authentication. On Linux you will be using SQL Server Authentication. If you specify Windows Authentication then SQL Server will use a trusted connection to your SQL Server using your Windows credentials without requiring a username and password. If SQL Server Authentication is specified and SQL Authentication is enabled on your SQL Server then you will be able connect by specifying a username and password that you have already configured on your SQL Server. Microsoft Entra Authentication can also be used with a minimum of ODBC Driver 18 and SQL Server 2022. Where Entra is used an MSI Object ID can also be specified. If Entra is chosen and the MSI Object ID is set to null then Interactive Entra Authentication will be used prompting for login credentials. |
| SQL Server User ID | The SQL Server User ID is the User ID of a user that you have already created on your SQL Server. |
| SQL Server User Password | The SQL Server User Password is the Password configured on the SQL Server for the User ID you have specified. Note that when configuring the password on the SQL Server there is a checkbox that when selected enforces more complex rules for passwords or if unchecked enables a simple password such as “admin”. |
| TRPOC-C SQL Server Database | The SQL Server Database is the name of the Database to be created on the SQL Server to contain the schema. If this database does not already exist then HammerDB will create it, if the database does already exist and the database is empty then HammerDB will use this existing database. Therefore if you wish to create a particular layout or schema then pre-creating the database and using this database is an advanced method to use this configuration. |
| In-Memory OLTP | Creates the database as In-Memory OLTP. The database must be pre-created in a MEMORY_OPTIMIZED_DATA filegroup and empty to specify an In-Memory build. |
| In-Memory Hash bucket Multiplier | The size of the In-memory database is specified at creation time, however the OLTP/TPROC-C schema allows for the insertion of additional rows. This value enables the creation of larger tables for orders, new_order and order_line to allow for these inserts. Note: Do not specify too large a value or the table creation will fail or performance will be significantly impacted. Typically the default value of 1 is sufficient and will suffice for manually run tests. For autopilot tests where are large number of tests are to be run a value of 3 or 4 will typically be sufficient, however of course the number of inserts will depend on the performance of the system under test and therefore testing is the best way to determine the correct schema size for a particular environment. |
| in-Memory Durability | Sets the durability option. If SCHEMA_ONLY is chosen when SQL Server is stopped only the tables remain without data loaded. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally on this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |
| Use BCP Option | This option uses the SQL Server BCP utility to bulk load data. Temporary staging files will be created and deleted in the location defined by the TEMP environment variable. When unselected an insert based build is used. A BCP build offers vastly improved performance over an insert based build. |
Note that as previously described the host and port are defined externally in the db2dsdriver.cfg file.
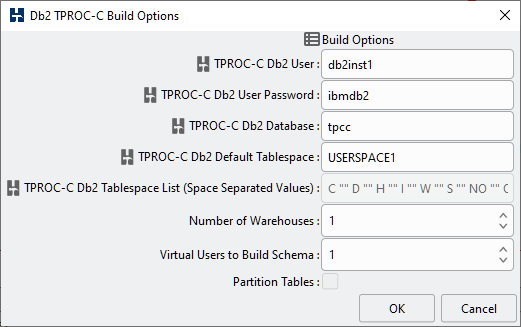
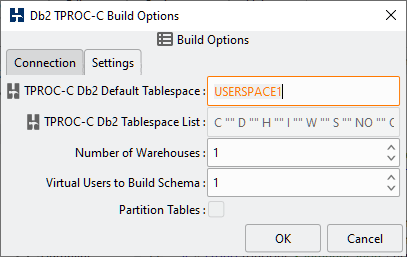
Table 4.3. Db2 Build Options
| Option | Description |
|---|---|
| TPROC-C Db2 User | The name of the operating system user to connect to the DB2 database for example db2inst1. |
| TPROC-C Db2 Password | The password for the operating system DB2 user by default “ibmdb2” |
| TPROC-C Db2 Database | The name of the Db2 database that you have already created, for example “tpcc” |
| TPROC-C Db2 Default Tablespace | The name of the existing tablespace where tables should be located if a specific tablespace has not been defined for that table in the tablespace list. The default is “USERSPACE1”. |
| TPROC-C Db2 Tablespace List (Space Separated Values) | When partitioning is selected, a space separated list of Tablespace initials followed by a pre-existing tablespace name in double-quotes into which to install a specific table. If no tablespace is given for a specific table then the default tablespace is used. The values are C: CUSTOMER D: DISTRICT H: HISTORY I: ITEM W: WAREHOUSE S: STOCK NO: NEW_ORDER OR: ORDERS OL: ORDER_LINE. And for example the following list, would create all tables in the default. C "" D "" H "" I "" W "" S "" NO "" OR "" OL "". Whereas the following would create the ITEM table in the ITEM_TS tablespace, the STOCK table in the STOCK_TS tablespace and the other tables in the default. C "" D "" H "" I "ITEM_TS" W "" S "STOCK_TS" NO "" OR "" OL "". You may configure all or no distinct tablespaces according to your requirements. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally on this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |
| Partition Tables | This check option becomes active when more than 10 warehouses are configured and transparently divides the schema into 10 separate tables for the larger tables for improved scalability and performance. This option is recommended for larger configurations. |
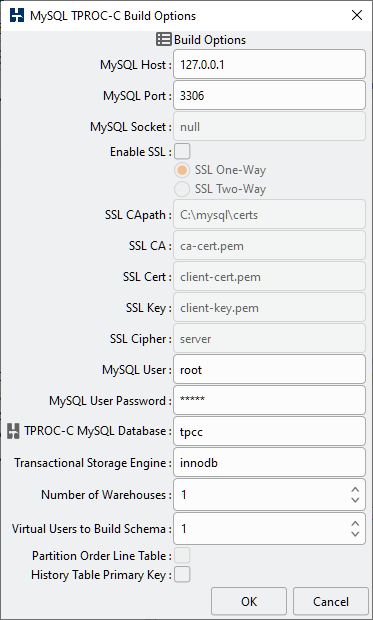
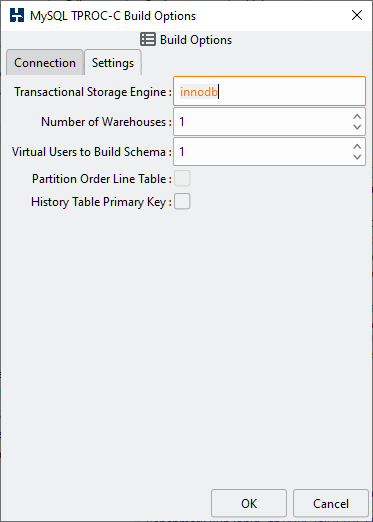
Table 4.4. MySQL Build Options
| Option | Description |
|---|---|
| MySQL Host | The MySQL Host Name is the host name that your load generation server will use to connect to the database running on the SUT database server. |
| MySQL Port | The MySQL Port is the network port that your load generation server will use to connect to the database running on the SUT database server. In most cases this will be the default port of 3306. |
| MySQL Socket | The MySQL Socket option is enabled on Linux only. If HammerDB is running on the same server and the MySQL Host is 127.0.0.1 or localhost then HammerDB will open a connection on the socket given instead of using TCP/IP. To force the use of the port instead of the socket on the localhost set the socket value to "null". |
| Enable SSL | Enable SSL permits SSL/TLS encryption on the network connection to MySQL with the option of choosing One-Way or Two-Way encryption. |
| SSL CApath | If the SSL CA, SSL Cert and SSL Key entries are empty HammerDB will pass the value in SSL CApath as the SSL capath option. If the SSL CA, SSL Cert and SSL Key entries contain the names of .pem files then the SSL CApath path option will be appended to these file names and used to locate these files. |
| SSL CA | The name of the SSL CA .pem file in the SSL CApath directory. |
| SSL Cert | The name of the SSL Cert .pem file in the SSL CApath directory. |
| SSL Key | The name of the SSL Key .pem file in the SSL CApath directory. |
| SSL Cipher | The default of SSL Cipher is "server" meaning that the server-side selected cipher is used. Alternatively this option can be used to specify a different cipher. The Cipher used will be reported by each Virtual User on connection. If the value is shown as {} then SSL is not enabled. |
| MySQL User | The MySQL User is the user which has permission to create a database and you previously granted access to from the load generation server. The root user already exists in all MySQL databases and has the necessary permissions to create the TPROC-C database. |
| MySQL User Password | The MySQL user password is the password for the user defined as the MySQL User. You will need to remember the MySQL user name and password for running the TPROC-C driver script after the database is built. |
| TPROC-C MySQL Database | The MySQL Database is the database that will be created containing the TPROC-C schema creation. There must have sufficient free space for the database to be created. |
| Transactional Storage Engine | Use the "show engine" command to display available storage engines and select a storage engine that supports transactions. By default set to InnoDB. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally n this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |
| Partition Order Line Table | Partition Order Line Table for improved scalability. |
| History Table Primary Key | In the TPC-C specification that the HammerDB TPROC-C workload is derived from the history table does not have a primary key. However for MySQL replication all tables must have a primary key. This option creates the history table with an invisible primary key at supported MySQL versions. |
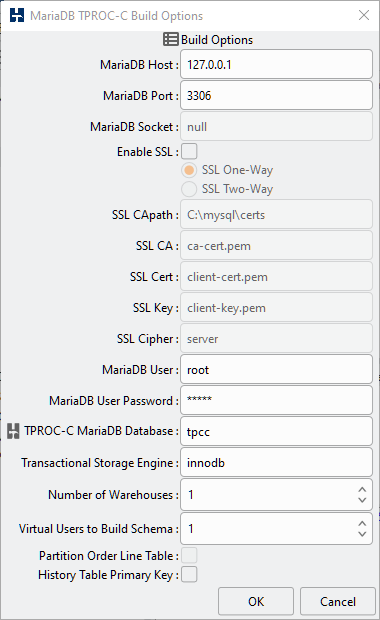
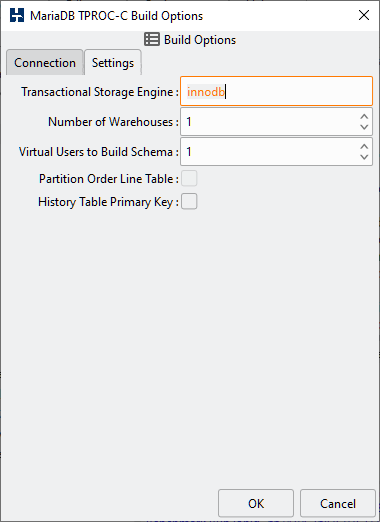
Table 4.5. MariaDB Build Options
| Option | Description |
|---|---|
| MariaDB Host | The MariaDB Host Name is the host name that your load generation server will use to connect to the database running on the SUT database server. |
| MariaDB Port | The MariaDB Port is the network port that your load generation server will use to connect to the database running on the SUT database server. In most cases this will be the default port of 3306. |
| MariaDB Socket | The MariaDB Socket option is enabled on Linux only. If HammerDB is running on the same server and the MariaDB Host is 127.0.0.1 or localhost then HammerDB will open a connection on the socket given instead of using TCP/IP. To force the use of the port instead of the socket on the localhost set the socket value to "null". |
| Enable SSL | Enable SSL permits SSL/TLS encryption on the network connection to MariaDB with the option of choosing One-Way or Two-Way encryption. |
| SSL CApath | If the SSL CA, SSL Cert and SSL Key entries are empty HammerDB will pass the value in SSL CApath as the SSL capath option. If the SSL CA, SSL Cert and SSL Key entries contain the names of .pem files then the SSL CApath path option will be appended to these file names and used to locate these files. If the SSL CApath is an empty string then the SSL Cert and SSL Key entries will be used only. |
| SSL CA | The name of the SSL CA .pem file in the SSL CApath directory. |
| SSL Cert | The name of the SSL Cert .pem file in the SSL CApath directory. |
| SSL Key | The name of the SSL Key .pem file in the SSL CApath directory. |
| SSL Cipher | The default of SSL Cipher is "server" meaning that the server-side selected cipher is used. Alternatively this option can be used to specify a different cipher. The Cipher used will be reported by each Virtual User on connection. If the value is shown as {} then SSL is not enabled. |
| MariaDB User | The MariaDB User is the user which has permission to create a database and you previously granted access to from the load generation server. The root user already exists in all MariaDB databases and has the necessary permissions to create the TPROC-C database. |
| MariaDB User Password | The MariaDB user password is the password for the user defined as the MariaDB User. You will need to remember the MariaDB user name and password for running the TPROC-C driver script after the database is built. If SSL authentication is being used it is also possible to enter "null" for the password to skip passing a password and use SSL authentication only. |
| TRPOC-C MariaDB Database | The MariaDB Database is the database that will be created containing the TPROC-C schema creation. There must have sufficient free space for the database to be created. |
| Transactional Storage Engine | Use the "show engine" command to display available storage engines and select a storage engine that supports transactions. By default set to InnoDB. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally n this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |
| Partition Order Line Table | Partition Order Line Table for improved scalability. |
| History Table Primary Key | In the TPC-C specification that the HammerDB TPROC-C workload is derived from the history table does not have a primary key. However for MySQL replication all tables must have a primary key. This option creates the history table with an invisible primary key at supported MySQL versions. |
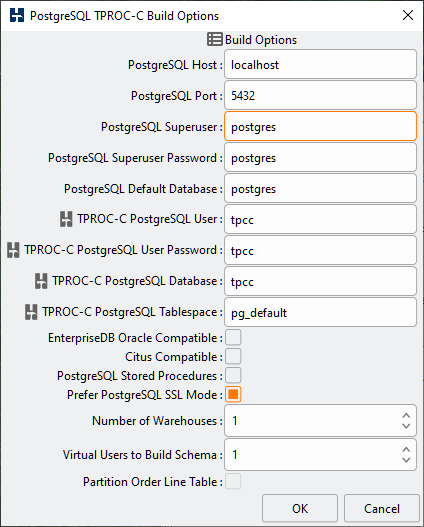
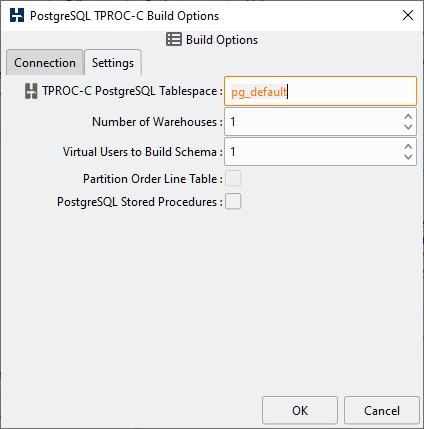
Table 4.6. PostgreSQL Build Options
| Option | Description |
|---|---|
| PostgreSQL Host | The host name of the SUT running PostgreSQL which the load generation server running HammerDB will connect to. |
| PostgreSQL Port | The port of the PostgreSQL service. By default this will be 5432 for a standard PostgreSQL installation or 5444 for EnterpriseDB. |
| PostgreSQL Superuser | The PostgreSQL Superuser is a user with sufficient privileges to create both new users (roles) and databases to enable the creation of the test schema. |
| PostgreSQL Superuser Password | The PostgreSQL Superuser Password is the password for the PostgreSQL superuser which will have been defined during installation. If you have forgotten the password it can be reset from a psql prompt that has logged in from a trusted connection therefore requiring no password using postgres=# alter role postgres password ‘postgres’; |
| PostgreSQL Default Database | The PostgreSQL default databases is the database to specify for the superuser connection. Typically this will be postgres for a standard PostgreSQL installation or edb for EnterpriseDB. |
| TPROC-C PostgreSQL User | The PostgreSQL User is the user (role) that will be created that owns the database containing the TPROC-C schema. |
| TPROC-C PostgreSQL User Password | The PostgreSQL User Password is the password that will be specified for the PostgreSQL user when it is created. |
| TPROC-C PostgreSQL Database | The PostgreSQL Database is the database that if it does not already exist will be created and owned by the PostgreSQL User that contains the TPROC-C schema. If the named database has already been created and is empty then that database will be used to create the schema. |
| TPROC-C PostgreSQL Tablespace | The PostgreSQL Tablespace in which to create the schema. By default the tablespace is pg_default. |
| EnterpriseDB Oracle Compatible | Choosing EnterpriseDB Oracle compatible creates a schema using the Oracle compatible features of EnterpriseDB in an installation of Postgres Plus Advanced Server. This build uses Oracle PL/SQL for the creation of the stored procedures. |
| PostgreSQL Stored Procedures | When running on PostgreSQL v11 or upwards use PostgreSQL stored procedures instead of functions. |
| Citus Compatible | Installs a schema into a PostgreSQL database with the Citus Data Distributed PostgreSQL extension. |
| Prefer PostgreSQL SSL Mode | If both the PostgreSQL client and server have been compiled to support SSL this option when selected enables "prefer" SSL, when unselected it sets this option to "disable" for connections. Other valid options such as "allow" or "require" can be set directly in the build and driver scripts if required. |
| Number of Warehouses | The Number of Warehouses is selected by a listbox. You should set this value to number of warehouses you have chosen for your test. |
| Virtual Users to Build Schema | The Virtual Users to Build Schema is the number of Virtual Users to be created on the Load Generation Server that will complete your multi-threaded schema build. You should set this value to either the number of warehouses you are going to create (You cannot set the number of virtual users higher than the number of warehouses value) or the number of cores/Hyper-Threads on your Load Generation Server. If you have a significantly larger core/Hyper-Thread count on your Database Server then also installing HammerDB locally on this server as well to run the schema build can take advantage of the higher core count to run the build more quickly. |