To begin the schema creation select the Build Option from the tree-view.
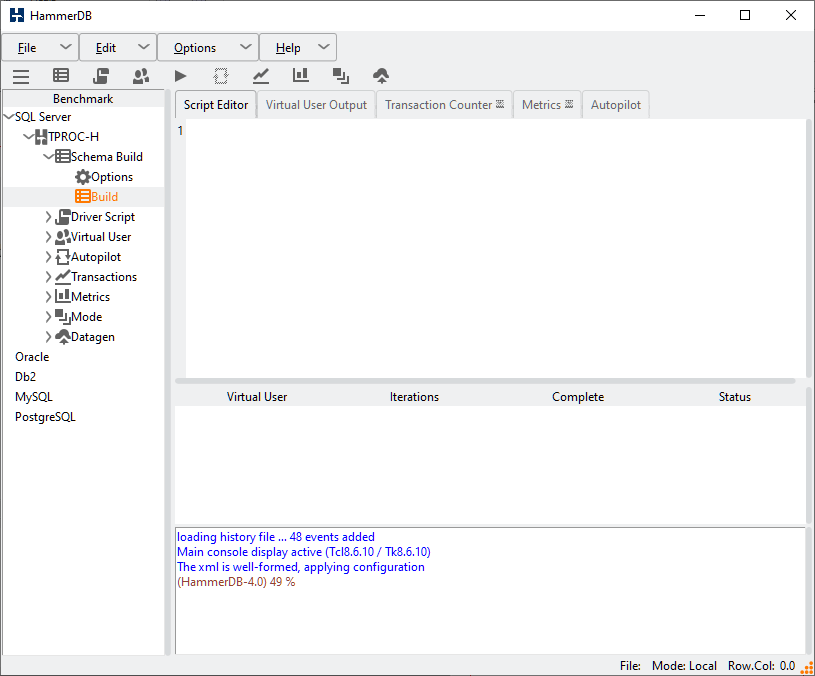
A dialog box is shown to confirm the options selected.
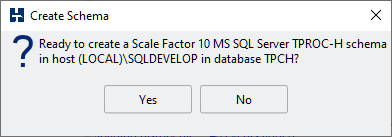
When you click Yes HammerDB will login to your chosen service name with a monitor thread as the system user and create the user with the password you have chosen. It will then log out and log in again as your chosen user, create the tables and then load the region and nation table data before waiting and monitoring the other threads. The worker threads will wait for the monitor thread to complete its initial work. Subsequently the worker threads will create and insert the data for their assigned warehouses. There are no intermediate data files or manual builds required, HammerDB will both create and load your requested data dynamically. Data is inserted in a batch format for optimal performance, however for larger schemas doing a bulk load of data created with the datagen feature will be a faster way to create the schema as it bypasses the logging and consistency checks of the insert based load.
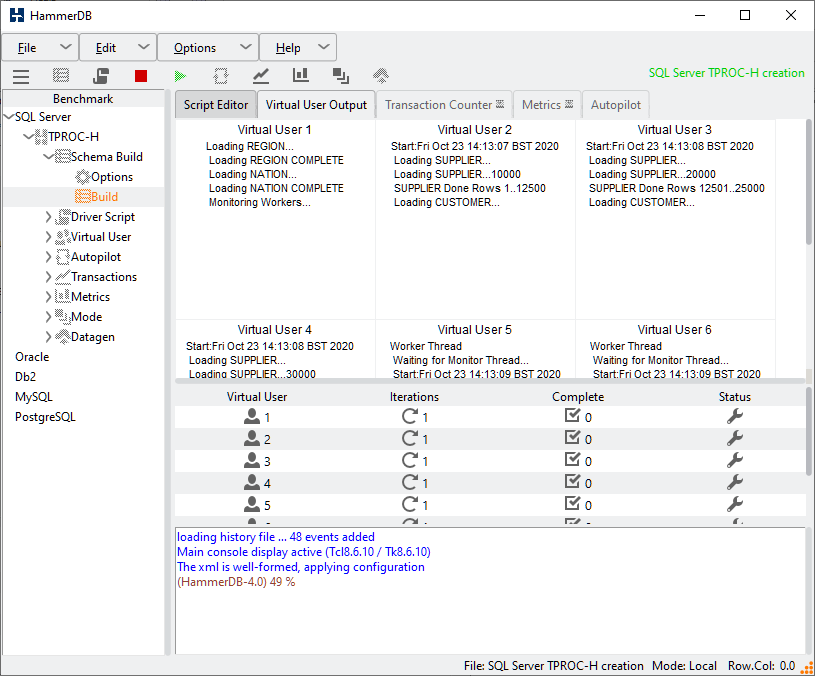
When the workers are complete the monitor thread will create the indexes and gather the statistics. When complete Virtual User 1 will display the message TPCH SCHEMA COMPLETE and all virtual users will show that they completed their action successfully. Pressing the red button will destroy the Virtual Users.
The schema build is now complete with the following tables created and populated. Note that in example below the tables have inherited the tablespaces’s in-memory configuration without additional settings. If required the inmemory_priority can also be set at this point in time.
1* select table_name, num_rows, inmemory, inmemory_priority from user_tables SQL> / TABLE_NAME NUM_ROWS INMEMORY INMEMORY_PRIORITY ------------------------------ ---------- -------- ----------------- ORDERS 1500000 ENABLED NONE PARTSUPP 800000 ENABLED NONE CUSTOMER 150000 ENABLED NONE PART 200000 ENABLED NONE SUPPLIER 10000 ENABLED NONE NATION 25 ENABLED NONE REGION5 5 ENABLED NONE LINEITEM 6003632 ENABLED NONE
You can verify the contents with SQL*PLUS as the newly created user.
SQL> select tname, tabtype from tab;
TNAME TABTYPE
------------------------------ -------
CUSTOMER TABLE
LINEITEM TABLE
NATION TABLE
ORDERS TABLE
PART TABLE
PARTSUPP TABLE
REGION TABLE
SUPPLIER TABLE
8 rows selected.
SQL> select * from customer where rownum = 1;
C_CUSTKEY C_MKTSEGME C_NATIONKEY C_NAME
---------- ---------- ----------- -------------------------
C_ADDRESS C_PHONE C_ACCTBAL
---------------------------------------- --------------- ----------
C_COMMENT
--------------------------------------------------------------------------------
112098 AUTOMOBILE 22 Customer#000112098
v,QXkbT8YhhyQYXjX4Ag3iFPQq0gbfZNo7 776-160-1375 5010.19
carefully pending instructions detect slyly-- pending deposits acco
SQL> select index_name, index_type from ind;
INDEX_NAME INDEX_TYPE
------------------------------
REGION_PK NORMAL
NATION_PK NORMAL
SUPPLIER_PK NORMAL
PARTSUPP_PK NORMAL
PART_PK NORMAL
ORDERS_PK NORMAL
LINEITEM_PK NORMAL
CUSTOMER_PK NORMAL
8 rows selected.
At this point the data creation is complete and you are ready to start running a performance test. Before doing so note that as this is a query based workload you have the potential to run multiple tests and it will return the same results as the data is not modified during tests, however there is one exception, under the Driver Options the option to choose a Refresh Function. Further details will be given on the refresh function in the next section however at this point it is sufficient to note that the refresh function when enabled will modify data and no two same refresh functions can be run on the same data set. This means if you choose to include a refresh function and then attempt to re-run the test you will receive an error as the data has been modified. This means you have a number of options. Firstly (and recommended) you can use datapump to backup and restore your schema. To do this create a directory as follows to reference a file system folder you have already created (or use the pre-existing DATA_PUMP_DIR)
SQL> create directory dump_dir1 as '/u02/app/oracle/dumpdir'; Directory created. Then use datapump to export your schema to this directory before you have run any workloads with a refresh function: [oracle@MERLIN oracle]$ expdp \"sys/oracle@pdb1 as sysdba\" schemas=tpch content=all directory=DUMP_DIR1 logfile=dp.log Export: Release 12.1.0.2.0 - Production on Wed Sep 17 11:23:32 2014 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options Starting "SYS"."SYS_EXPORT_SCHEMA_01": "sys/********@pdb1 AS SYSDBA" schemas=tpch content=all directory=DUMP_DIR1 logfile=dp.log Estimate in progress using BLOCKS method... Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 1.159 GB Processing object type SCHEMA_EXPORT/USER Processing object type SCHEMA_EXPORT/SYSTEM_GRANT Processing object type SCHEMA_EXPORT/ROLE_GRANT Processing object type SCHEMA_EXPORT/DEFAULT_ROLE Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Processing object type SCHEMA_EXPORT/STATISTICS/MARKER . . exported "TPCH"."LINEITEM" 746.2 MB 6003632 rows . . exported "TPCH"."ORDERS" 165.4 MB 1500000 rows . . exported "TPCH"."PARTSUPP" 112.7 MB 800000 rows . . exported "TPCH"."PART" 25.99 MB 200000 rows . . exported "TPCH"."CUSTOMER" 23.45 MB 150000 rows . . exported "TPCH"."SUPPLIER" 1.430 MB 10000 rows . . exported "TPCH"."NATION" 9.125 KB 25 rows . . exported "TPCH"."REGION" 6.476 KB 5 rows Master table "SYS"."SYS_EXPORT_SCHEMA_01" successfully loaded/unloaded ****************************************************************************** Dump file set for SYS.SYS_EXPORT_SCHEMA_01 is: /u02/app/oracle/dumpdir/expdat.dmp Job "SYS"."SYS_EXPORT_SCHEMA_01" successfully completed at Wed Sep 17 11:24:10 2014 elapsed 0 00:00:36
After you have run a workload with a refresh function drop the TPROC-H user as follows:
SQL> drop user tpch cascade; User dropped.
Then re-import the export file you took prior to running the refresh function:
[oracle@MERLIN oracle]$ impdp \"sys/oracle@pdb1 as sysdba\" schemas=tpch content=all directory=DUMP_DIR1 logfile=dp1.log Import: Release 12.1.0.2.0 - Production on Wed Sep 17 11:37:54 2014 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options Master table "SYS"."SYS_IMPORT_SCHEMA_04" successfully loaded/unloaded Starting "SYS"."SYS_IMPORT_SCHEMA_04": "sys/********@pdb1 AS SYSDBA" schemas=tpch content=all directory=DUMP_DIR1 logfile=dp1.log Processing object type SCHEMA_EXPORT/USER Processing object type SCHEMA_EXPORT/SYSTEM_GRANT Processing object type SCHEMA_EXPORT/ROLE_GRANT Processing object type SCHEMA_EXPORT/DEFAULT_ROLE Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . imported "TPCH"."LINEITEM" 746.2 MB 6003632 rows . . imported "TPCH"."ORDERS" 165.4 MB 1500000 rows . . imported "TPCH"."PARTSUPP" 112.7 MB 800000 rows . . imported "TPCH"."PART" 25.99 MB 200000 rows . . imported "TPCH"."CUSTOMER" 23.45 MB 150000 rows . . imported "TPCH"."SUPPLIER" 1.430 MB 10000 rows . . imported "TPCH"."NATION" 9.125 KB 25 rows . . imported "TPCH"."REGION" 6.476 KB 5 rows Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Processing object type SCHEMA_EXPORT/STATISTICS/MARKER Job "SYS"."SYS_IMPORT_SCHEMA_04" successfully completed at Wed Sep 17 11:38:40 2014 elapsed 0 00:00:44
You only need to export once and can then re-import as many times as you wish to run the successfully refresh function.
Secondly another option you have is to use dbms_metadata to capture the table definitions and then use SQL*Loader to export and import the data using the datagen created data. Finally if you have the flashback table feature enabled you can note the time that you start running a test with a refresh function and then flashback the LINEITEM and ORDERS table to their previous state before the test, for example:
flashback table lineitem to timestamp TO_TIMESTAMP('17-SEP-14 11.41.00.00 AM')Whichever method you use, ensure that if you wish to run the refresh function you are prepared to restore your schema to the previous state before running subsequent tests.
Once created you can verify the schema with SSMS or sqlcmd.
C:\Users>sqlcmd -S (local)\SQLDEVELOP -E -Q "use tpch; select name from sys.tables" Changed database context to 'tpch'. name -------------------------------------------------------------------------------- customer lineitem nation part partsupp region supplier orders (8 rows affected)
At this point the data creation is complete and you are ready to start running a performance test. Before doing so note that as this is a query based workload you have the potential to run multiple tests and it will return the same results as the data is not modified during tests, however there is one exception, under the Driver Options the option to choose a Refresh Function. Further details will be given on the refresh function in the next section however at this point it is sufficient to note that the refresh function when enabled will modify data and no two same refresh functions can be run on the same data set. This means if you choose to include a refresh function and then attempt to re-run the test you will receive an error as the data has been modified. Therefore you should backup your schema before running a workload.

SQL Server will notify when the backup is successful.

The restore can also be selected from the tasks option.
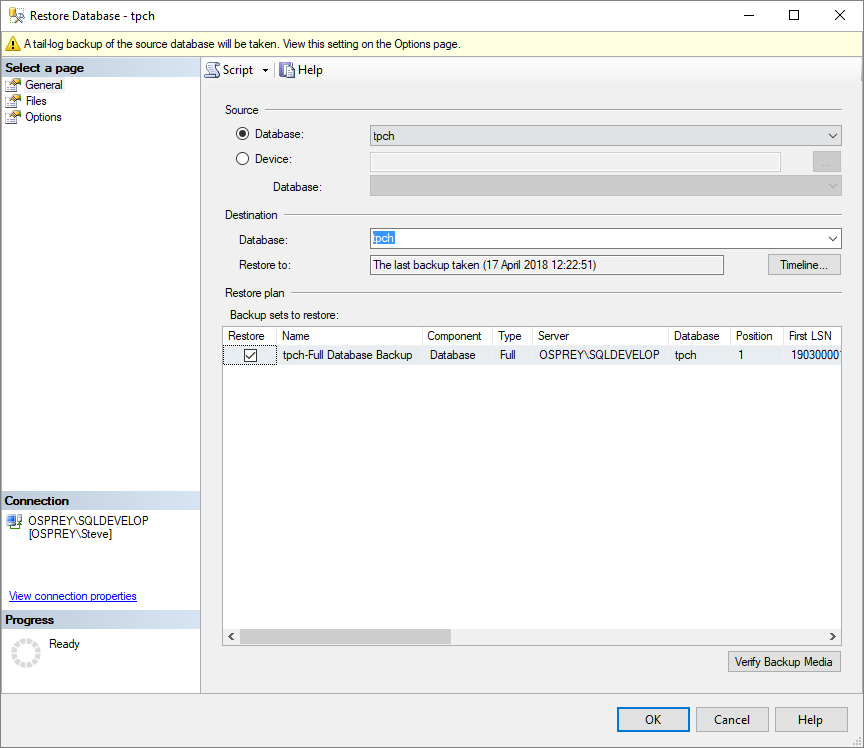
and notification given when the database is restored.

The schema build is now complete with the following tables created and populated with the example showing a scale factor 10 schema.
db2 => select tabname, card from syscat.tables where tabschema = 'DB2INST1'
TABNAME CARD
---------------------------------- --------------------
CUSTOMER 1500000
LINEITEM 60001587
NATION 25
ORDERS 15000000
PART 2000000
PARTSUPP 8000000
REGION 5
SUPPLIER 100000
8 record(s) selected.
db2 => select * from customer fetch first row only
C_CUSTKEY C_NAME C_ADDRESS C_NATIONKEY C_PHONE C_ACCTBAL C_MKTSEGMENT C_COMMENT
----------- ------------------------- ---------------------------------------- ----------- --------------- ------------------------ ------------ -------------------------------------------------------
1128378 Customer#001128378 OzpJsusYMT 6 651-964-1273 +9.57891000000000E+003 HOUSEHOLD ironic requests above the furiously special foxes wake
1 record(s) selected.
db2 =>
At this point the data creation is complete and you are ready to start running a performance test. Before doing so note that as this is a query based workload you have the potential to run multiple tests and it will return the same results as the data is not modified during tests, however there is one exception, under the Driver Options the option to choose a Refresh Function. Further details will be given on the refresh function in the next section however at this point it is sufficient to note that the refresh function when enabled will modify data and no two same refresh functions can be run on the same data set. This means if you choose to include a refresh function and then attempt to re-run the test you will receive an error as the data has been modified. This means that it is strongly recommended to backup or export your data before running a refresh function to ensure that if you wish to run the refresh function multiple times you are prepared to restore your schema to the previous state before running subsequent tests.
$ db2 backup db tpch to /opt/db2/backup Backup successful. The timestamp for this backup image is : 20180417181222 $ db2 restore db tpch from /opt/db2/backup replace existing SQL2539W The specified name of the backup image to restore is the same as the name of the target database. Restoring to an existing database that is the same as the backup image database will cause the current database to be overwritten by the backup version. DB20000I The RESTORE DATABASE command completed successfully.
It is useful to reiterate that before running a query test for all configurations you must make the following setting in the sb2cli.ini file.
[db2inst1 cfg]$ more db2cli.ini [TPCH] IgnoreWarnList="'01003'"
Failure to add this setting for each virtual user will result in the query set failing with the following error.
Error in Virtual User 3: [IBM][CLI Driver][DB2/NT64] SQLSTATE 01003: Null values were eliminated from the argument of a column function.
MySQL does not directly support analytic workloads, however where used the same verification and backup methodology can be used as given for MariaDB.
The schema build is now complete with the following tables created and populated with the example showing a scale factor 1 schema.
MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | tpch | +--------------------+ 4 rows in set (0.00 sec) MariaDB [(none)]> use tpch; Database changed MariaDB [tpch]> show tables; +----------------+ | Tables_in_tpch | +----------------+ | CUSTOMER | | LINEITEM | | NATION | | ORDERS | | PART | | PARTSUPP | | REGION | | SUPPLIER | +----------------+ 8 rows in set (0.00 sec)
At this point the data creation is complete and you are ready to start running a performance test. Before doing so note that as this is a query based workload you have the potential to run multiple tests and it will return the same results as the data is not modified during tests, however there is one exception, under the Driver Options the option to choose a Refresh Function. Further details will be given on the refresh function in the next section however at this point it is sufficient to note that the refresh function when enabled will modify data and no two same refresh functions can be run on the same data set. This means if you choose to include a refresh function and then attempt to re-run the test you will receive an error as the data has been modified. This means that it is strongly recommended to backup or export your data before running a refresh function to ensure that if you wish to run the refresh function multiple times you are prepared to restore your schema to the previous state before running subsequent tests.
./client/mysqldump -u root -pmysql tpch > backup-tpch.sql ./client/mysql -u root -pmysql Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 16 Server version: 10.1.25-MariaDB Source distribution Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> create database tpch; Query OK, 1 row affected (0.00 sec) MariaDB [(none)]> Bye ./client/mysql -u root -pmysql tpch < backup-tpch.sql ./client/mysql -u root -pmysql Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 18 Server version: 10.1.25-MariaDB Source distribution Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> use tpch Database changed MariaDB [tpch]> show tables; +----------------+ | Tables_in_tpch | +----------------+ | CUSTOMER | | LINEITEM | | NATION | | ORDERS | | PART | | PARTSUPP | | REGION | | SUPPLIER | +----------------+ 8 rows in set (0.00 sec) MariaDB [tpch]> select count(*) from LINEITEM; +----------+ | count(*) | +----------+ | 6000385 | +----------+ 1 row in set (0.00 sec)
The schema build is now complete with the following tables created and populated with the example showing a scale factor 1 schema.
$ ./bin/psql -d tpch psql (10.1) Type "help" for help. tpch=# select relname, n_tup_ins - n_tup_del as rowcount from pg_stat_user_tables; relname | rowcount ----------+---------- nation | 25 lineitem | 6000773 orders | 1497000 customer | 150000 region | 5 supplier | 10000 part | 200000 partsupp | 800000 (8 rows) tpch=#
At this point the data creation is complete and you are ready to start running a performance test. Before doing so note that as this is a query based workload you have the potential to run multiple tests and it will return the same results as the data is not modified during tests, however there is one exception, under the Driver Options the option to choose a Refresh Function. Further details will be given on the refresh function in the next section however at this point it is sufficient to note that the refresh function when enabled will modify data and no two same refresh functions can be run on the same data set. This means if you choose to include a refresh function and then attempt to re-run the test you will receive an error as the data has been modified. This means that it is strongly recommended to backup or export your data before running a refresh function to ensure that if you wish to run the refresh function multiple times you are prepared to restore your schema to the previous state before running subsequent tests.
pgsql$ ./bin/pg_dump tpch > pgdumpfile pgsql$ ./bin/psql psql (10.1) Type "help" for help. # drop database tpch; DROP DATABASE # drop role tpch; DROP ROLE # create user tpch password 'tpch'; CREATE ROLE # create database tpch owner tpch; CREATE DATABASE pgsql$ cat pgdumpfile | ./bin/psql tpch SET SET SET SET ....