This section includes advanced driver script options intended for expert usage. These options can be used independently or simultaneously for advanced testing scenarios.
By default each Virtual User will select one home warehouse at random and keep that home warehouse for the duration of a run meaning the majority of its workload will take place on a single warehouse. This means that when running for example 10 Virtual Users most of the workload will take place on 10 warehouses regardless of whether 100, 1000 or 10,000 are configured in the schema. Use All Warehouses is an option that enables increased I/O to the database data area by assigning all of the warehouses in the schema to the Virtual Users in turn. The Virtual Users will then select a new warehouse for each transaction. Consequently this means that the schema size impacts on the overall level of performance placing a great emphasis on I/O. To select this option check the Use All Warehouses check-box.
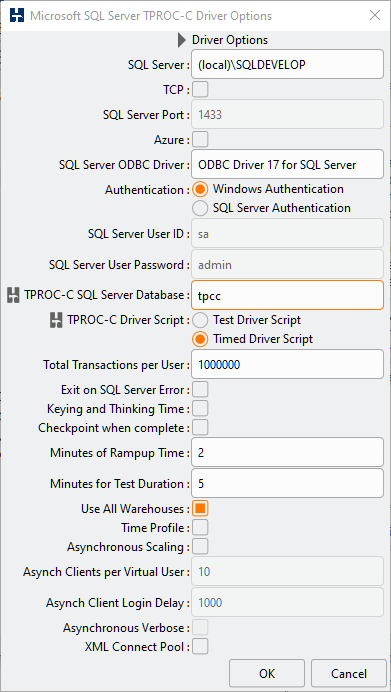
On running the workload it can now be seen that the Virtual Users will evenly assign the available warehouses between them.
The listing shows an example of a schema with 30 warehouses and 3 Virtual Users. This approach is particularly applicable when testing I/O capabilities for database.
Vuser 1:Beginning rampup time of 2 minutes Vuser 2:VU 2 : Assigning WID=1 based on VU count 3, Warehouses = 30 (1 out of 10) Vuser 2:VU 2 : Assigning WID=4 based on VU count 3, Warehouses = 30 (2 out of 10) Vuser 2:VU 2 : Assigning WID=7 based on VU count 3, Warehouses = 30 (3 out of 10) Vuser 2:VU 2 : Assigning WID=10 based on VU count 3, Warehouses = 30 (4 out of 10) Vuser 2:VU 2 : Assigning WID=13 based on VU count 3, Warehouses = 30 (5 out of 10) Vuser 2:VU 2 : Assigning WID=16 based on VU count 3, Warehouses = 30 (6 out of 10) Vuser 2:VU 2 : Assigning WID=19 based on VU count 3, Warehouses = 30 (7 out of 10) Vuser 2:VU 2 : Assigning WID=22 based on VU count 3, Warehouses = 30 (8 out of 10) Vuser 2:VU 2 : Assigning WID=25 based on VU count 3, Warehouses = 30 (9 out of 10) Vuser 2:VU 2 : Assigning WID=28 based on VU count 3, Warehouses = 30 (10 out of 10) Vuser 2:Processing 1000000 transactions with output suppressed... Vuser 3:VU 3 : Assigning WID=2 based on VU count 3, Warehouses = 30 (1 out of 10) Vuser 3:VU 3 : Assigning WID=5 based on VU count 3, Warehouses = 30 (2 out of 10) Vuser 3:VU 3 : Assigning WID=8 based on VU count 3, Warehouses = 30 (3 out of 10) Vuser 3:VU 3 : Assigning WID=11 based on VU count 3, Warehouses = 30 (4 out of 10) Vuser 3:VU 3 : Assigning WID=14 based on VU count 3, Warehouses = 30 (5 out of 10) Vuser 3:VU 3 : Assigning WID=17 based on VU count 3, Warehouses = 30 (6 out of 10) Vuser 3:VU 3 : Assigning WID=20 based on VU count 3, Warehouses = 30 (7 out of 10) Vuser 3:VU 3 : Assigning WID=23 based on VU count 3, Warehouses = 30 (8 out of 10) Vuser 3:VU 3 : Assigning WID=26 based on VU count 3, Warehouses = 30 (9 out of 10) Vuser 3:VU 3 : Assigning WID=29 based on VU count 3, Warehouses = 30 (10 out of 10) Vuser 3:Processing 1000000 transactions with output suppressed... Vuser 4:VU 4 : Assigning WID=3 based on VU count 3, Warehouses = 30 (1 out of 10) Vuser 4:VU 4 : Assigning WID=6 based on VU count 3, Warehouses = 30 (2 out of 10) Vuser 4:VU 4 : Assigning WID=9 based on VU count 3, Warehouses = 30 (3 out of 10) Vuser 4:VU 4 : Assigning WID=12 based on VU count 3, Warehouses = 30 (4 out of 10) Vuser 4:VU 4 : Assigning WID=15 based on VU count 3, Warehouses = 30 (5 out of 10) Vuser 4:VU 4 : Assigning WID=18 based on VU count 3, Warehouses = 30 (6 out of 10) Vuser 4:VU 4 : Assigning WID=21 based on VU count 3, Warehouses = 30 (7 out of 10) Vuser 4:VU 4 : Assigning WID=24 based on VU count 3, Warehouses = 30 (8 out of 10) Vuser 4:VU 4 : Assigning WID=27 based on VU count 3, Warehouses = 30 (9 out of 10) Vuser 4:VU 4 : Assigning WID=30 based on VU count 3, Warehouses = 30 (10 out of 10)
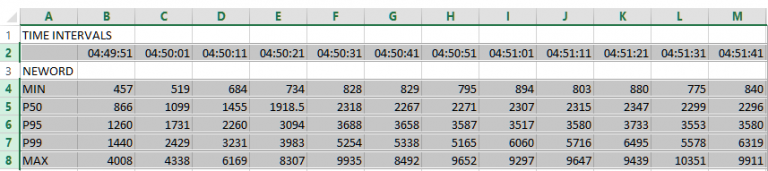
In addition to performance profiles based on throughput you should also take note of transaction response times. Whereas performance profiles show the cumulative performance of all of the virtual users running on the system, response times show performance based on the experience of the individual user. When comparing systems both throughput and response time are important comparative measurements. HammerDB includes a time profiling package called etprof that enables you to select an individual user and measure the response times. This functionality is enabled by selecting Time Profile checkbox in the driver options. When enabled the time profile will show response time percentile values at 10 second intervals, reporting the minimum, 50th percentile, 95th percentile, 99th percentile and maximum for each of the procedures during that 10 second interval as well as cumulative values for all of the test at the end of the test run. The time profile values are recorded in microseconds.
Hammerdb Log @ Fri Jul 05 09:55:26 BST 2019 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- Vuser 1:Beginning rampup time of 1 minutes Vuser 2:Processing 1000000 transactions with output suppressed... Vuser 3:Processing 1000000 transactions with output suppressed... Vuser 4:Processing 1000000 transactions with output suppressed... Vuser 5:Processing 1000000 transactions with output suppressed... Vuser 2:|PERCENTILES 2019-07-05 09:55:46 to 2019-07-05 09:55:56 Vuser 2:|neword|MIN-391|P50%-685|P95%-1286|P99%-3298|MAX-246555|SAMPLES-3603 Vuser 2:|payment|MIN-314|P50%-574|P95%-1211|P99%-2253|MAX-89367|SAMPLES-3564 Vuser 2:|delivery|MIN-1128|P50%-1784|P95%-2784|P99%-6960|MAX-267012|SAMPLES-356 Vuser 2:|slev|MIN-723|P50%-884|P95%-1363|P99%-3766|MAX-120687|SAMPLES-343 Vuser 2:|ostat|MIN-233|P50%-568|P95%-1325|P99%-2387|MAX-82538|SAMPLES-365 Vuser 2:|gettimestamp|MIN-2|P50%-4|P95%-7|P99%-14|MAX-39|SAMPLES-7521 Vuser 2:|prep_statement|MIN-188|P50%-209|P95%-1067|P99%-1067|MAX-1067|SAMPLES-6 Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ ... Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ Vuser 2:|PERCENTILES 2019-07-05 09:59:26 to 2019-07-05 09:59:36 Vuser 2:|neword|MIN-410|P50%-678|P95%-1314|P99%-4370|MAX-32030|SAMPLES-4084 Vuser 2:|payment|MIN-331|P50%-583|P95%-1271|P99%-3152|MAX-43996|SAMPLES-4142 Vuser 2:|delivery|MIN-1177|P50%-2132|P95%-3346|P99%-4040|MAX-8492|SAMPLES-416 Vuser 2:|slev|MIN-684|P50%-880|P95%-1375|P99%-1950|MAX-230733|SAMPLES-364 Vuser 2:|ostat|MIN-266|P50%-688.5|P95%-1292|P99%-1827|MAX-9790|SAMPLES-427 Vuser 2:|gettimestamp|MIN-3|P50%-4|P95%-7|P99%-14|MAX-22|SAMPLES-8639 Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ Vuser 2:|PERCENTILES 2019-07-05 09:59:36 to 2019-07-05 09:59:46 Vuser 2:|neword|MIN-404|P50%-702|P95%-1296|P99%-4318|MAX-71663|SAMPLES-3804 Vuser 2:|payment|MIN-331|P50%-597|P95%-1250|P99%-4190|MAX-47539|SAMPLES-3879 Vuser 2:|delivery|MIN-1306|P50%-2131|P95%-4013|P99%-8742|MAX-25095|SAMPLES-398 Vuser 2:|slev|MIN-713|P50%-913|P95%-1438|P99%-2043|MAX-7434|SAMPLES-386 Vuser 2:|ostat|MIN-268|P50%-703|P95%-1414|P99%-3381|MAX-249963|SAMPLES-416 Vuser 2:|gettimestamp|MIN-3|P50%-4|P95%-8|P99%-16|MAX-27|SAMPLES-8079 Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ Vuser 1:3 ..., Vuser 1:Test complete, Taking end Transaction Count. Vuser 1:4 Active Virtual Users configured Vuser 1:TEST RESULT : System achieved 468610 SQL Server TPM at 101789 NOPM Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ Vuser 2:|PROCNAME | EXCLUSIVETOT| %| CALLNUM| AVGPERCALL| CUMULTOT| Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+ Vuser 2:|neword | 82051665|39.96%| 93933| 873| 88760245| Vuser 2:|payment | 73823956|35.95%| 93922| 786| 80531339| Vuser 2:|delivery | 22725292|11.07%| 9577| 2372| 23418195| Vuser 2:|slev | 14396765| 7.01%| 9340| 1541| 14402033| Vuser 2:|ostat | 10202116| 4.97%| 9412| 1083| 10207260| Vuser 2:|gettimestamp | 2149552| 1.05%| 197432| 10| 13436919| Vuser 2:|TOPLEVEL | 2431| 0.00%| 1| 2431| NOT AVAILABLE| Vuser 2:|prep_statement | 1935| 0.00%| 5| 387| 1936| Vuser 2:+-----------------+--------------+------+--------+--------------+--------------+
After capturing the response time the script below can be run at the command line and provided with a logfile with the data for one run only. Note that it is important that you only provide a logfile for one run of a HammerDB benchmark to convert, otherwise all of the data will be combined from multiple runs. When run on a logfile with data such as shown above this will output the data in tab delimited format that can be interpreted by a spreadsheet.
!/bin/tclsh
set filename [lindex $argv 0]
set fp [open "$filename" r]
set file_data [ read $fp ]
set data [split $file_data "\n"]
foreach line $data {
if {[ string match *PERCENTILES* $line ]} {
set timeval "[ lindex [ split $line ] 3 ]"
append xaxis "$timeval\t"
}
}
puts "TIME INTERVALS"
puts "\t$xaxis"
foreach storedproc {neword payment delivery slev ostat} {
puts [ string toupper $storedproc ]
foreach line $data {
if {[ string match *PROCNAME* $line ]} { break }
if {[ string match *$storedproc* $line ]} {
regexp {MIN-[0-9.]+} $line min
regsub {MIN-} $min "" min
append minlist "$min\t"
regexp {P50%-[0-9.]+} $line p50
regsub {P50%-} $p50 "" p50
append p50list "$p50\t"
regexp {P95%-[0-9.]+} $line p95
regsub {P95%-} $p95 "" p95
append p95list "$p95\t"
regexp {P99%-[0-9.]+} $line p99
regsub {P99%-} $p99 "" p99
append p99list "$p99\t"
regexp {MAX-[0-9.]+} $line max
regsub {MAX-} $max "" max
append maxlist "$max\t"
}
}
puts -nonewline "MIN\t"
puts $minlist
unset -nocomplain minlist
puts -nonewline "P50\t"
puts $p50list
unset -nocomplain p50list
puts -nonewline "P95\t"
puts $p95list
unset -nocomplain p95list
puts -nonewline "P99\t"
puts $p99list
unset -nocomplain p99list
puts -nonewline "MAX\t"
puts $maxlist
unset -nocomplain maxlist
}
close $fpPass the name of the logfile for the run where response times were captured and output them to a file with a spreadsheet extension name. Note that it is important to output the data to a file and not to a terminal with that data then cut and paste into a spreadsheet. If output to a terminal it may format the output by removing the tab characters which are essential to the formatting.
$ ./extracttp.tcl pgtp.log > pgtp.txt
With Excel 2013 and above you can give this file a .xls extension and open it. If you do it will give the following warning, however if you click OK it will open with the correctly formatted data.

Alternatively if we open the file with the .txt extension it will show 3 steps for the Text Import Wizard. Click through the Wizard until Finish, After clicking Finish the data has been imported into the spreadsheet without warnings. Highlight the rows you want to graph by clicking on the row numbers.
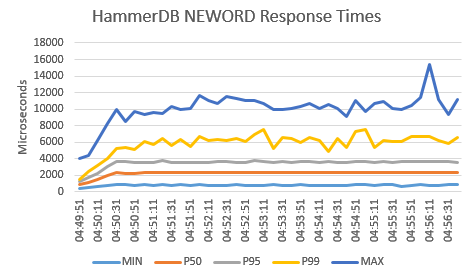
Click on Insert and Recommended Charts, the default graph produced by Excel is shown below with the addition of a vertical axis title and a chart header. When saving the spreadsheet it is saved in Excel format rather than the imported Tab (Text Delimited).
Event driven scaling enables the scaling of virtual users to thousands of sessions running with keying and thinking time enabled. This feature adds additional benefit to your testing scenarios with the ability to handle large numbers of connections or testing with connection pooling. When running transactional workloads with HammerDB the default mode is CPU intensive meaning that one virtual user will run as many transactions as possible without keying and thinking time enabled. When keying and thinking time is enabled there is a large time delay both before and after running a transaction meaning that each Virtual User will spend most of its time idle. However creating a very large number of Virtual Users requires a significant use of load test generation server resources. Consequently event driven scaling is a feature that enables each Virtual User to create multiple database sessions and manage the keying and thinking time for each asynchronously in an event-driven loop enabling HammerDB to create a much larger session count within an existing Virtual User footprint. It should be clear that this feature is only designed to work with keying and thinking time enabled as it is only the keying and thinking time that is managed asynchronously.
To configure this feature select Asynchronous Scaling noting that Keying and Thinking Time is automatically selected. Select a number of Asynch Clients per Virtual User and set the Asynch Login Delay in milliseconds. This Login Delay means that each client will wait for this time after the previous client has logged in before then logging in itself. For detailed output select Asynchronous Verbose. Note that with this feature it is important to allow the clients enough time to both login fully before measuring performance and also at the end it will take additional time for the clients to all complete their current keying and thinking time and to exit before the Virtual User reports all clients as complete.
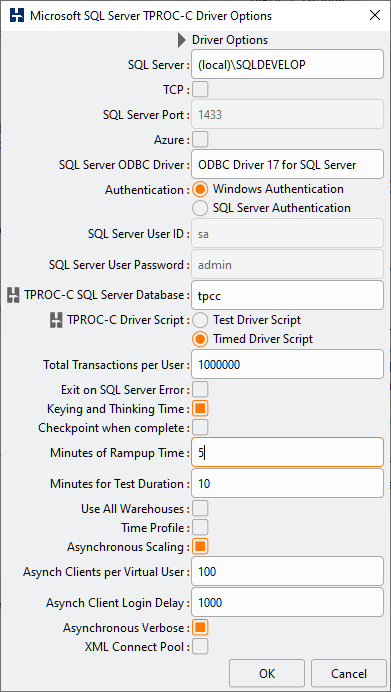
When all Virtual Users have logged in (example from SQL Server) the session count will show as the number of Virtual Users multiplied by the Asynchronous Clients.
SELECT DB_NAME(dbid) as DBName, COUNT(dbid) as NumberOfConnections FROM sys.sysprocesses WHERE dbid > 0 GROUP BY dbid;
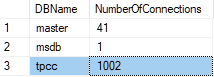
As each Asynchronous Client logs in it will be reported in the Virtual User output.
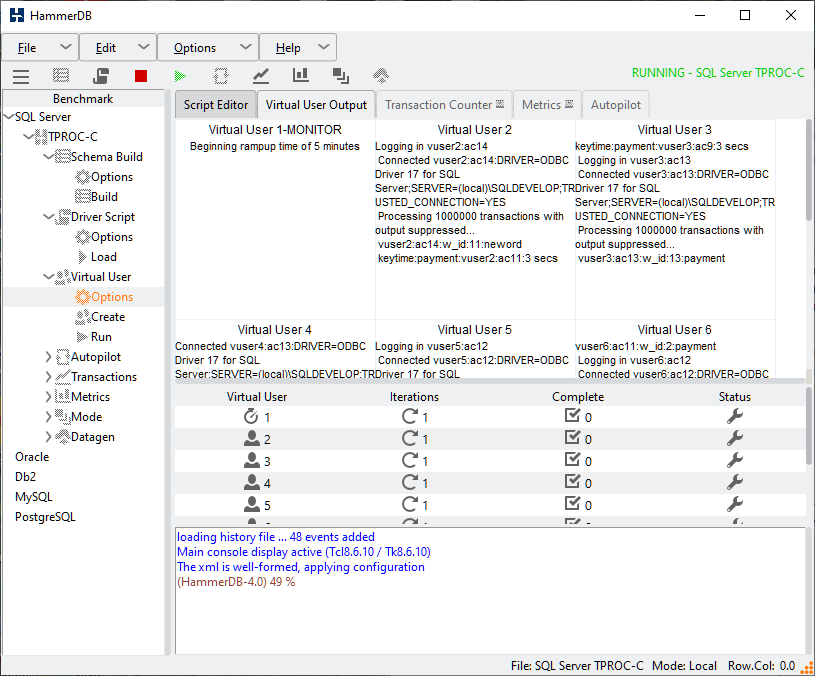
When the workload is running with Asynchronous Verbose enabled HammerDB will report the events as they happen.
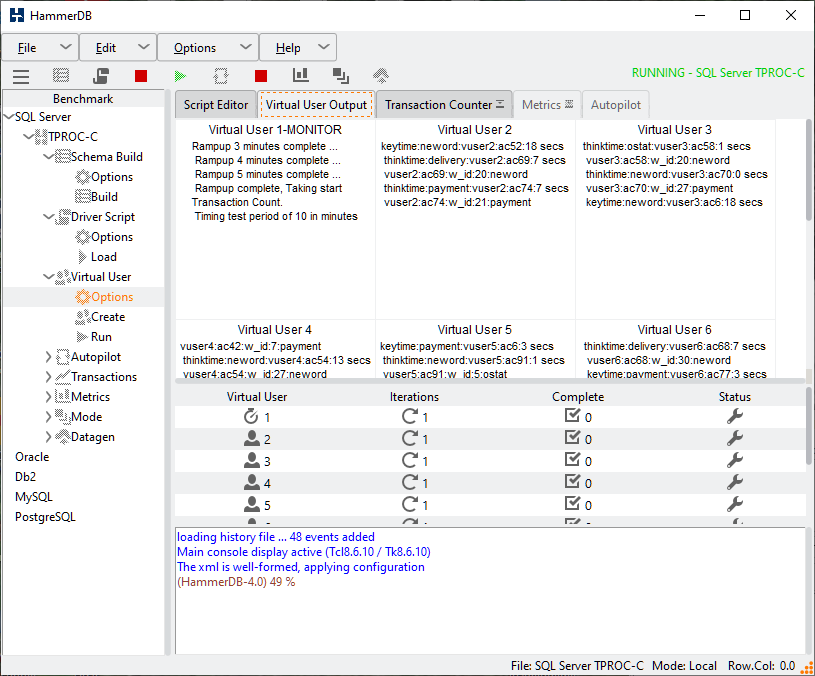
With logging enabled and Asynchronous Verbose HammerDB will report the events as they happen for each Virtual User such as when they enter keying or thinking time and when they process a transaction.
Vuser 6:keytime:payment:vuser6:ac9:3 secs Vuser 7:keytime:payment:vuser7:ac92:3 secs Vuser 7:thinktime:delivery:vuser7:ac77:3 secs Vuser 3:keytime:payment:vuser3:ac30:3 secs Vuser 9:keytime:delivery:vuser9:ac49:2 secs Vuser 7:vuser7:ac77:w_id:21:payment Vuser 9:keytime:neword:vuser9:ac64:18 secs Vuser 3:thinktime:neword:vuser3:ac72:15 secs Vuser 3:vuser3:ac72:w_id:4:payment Vuser 3:keytime:neword:vuser3:ac52:18 secs Vuser 7:thinktime:neword:vuser7:ac43:8 secs Vuser 7:vuser7:ac43:w_id:6:payment Vuser 7:keytime:ostat:vuser7:ac9:2 secs Vuser 3:keytime:payment:vuser3:ac9:3 secs Vuser 3:thinktime:payment:vuser3:ac97:7 secs Vuser 11:keytime:payment:vuser11:ac42:3 secs Vuser 5:keytime:neword:vuser5:ac42:18 secs Vuser 9:thinktime:ostat:vuser9:ac71:3 secs Vuser 3:vuser3:ac97:w_id:24:payment Vuser 9:vuser9:ac71:w_id:9:delivery Vuser 9:keytime:delivery:vuser9:ac69:2 secs Vuser 5:keytime:delivery:vuser5:ac19:2 secs Vuser 11:thinktime:neword:vuser11:ac53:13 secs Vuser 11:vuser11:ac53:w_id:8:neword Vuser 9:keytime:delivery:vuser9:ac2:2 secs Vuser 7:thinktime:neword:vuser7:ac81:12 secs Vuser 3:keytime:neword:vuser3:ac47:18 secs Vuser 7:vuser7:ac81:w_id:5:payment Vuser 3:keytime:payment:vuser3:ac81:3 secs Vuser 7:keytime:slev:vuser7:ac46:2 secs Vuser 11:thinktime:payment:vuser11:ac65:2 secs Vuser 11:vuser11:ac65:w_id:21:slev Vuser 9:keytime:neword:vuser9:ac86:18 secs Vuser 11:thinktime:payment:vuser11:ac20:1 secs Vuser 7:thinktime:neword:vuser7:ac76:9 secs Vuser 11:vuser11:ac20:w_id:6:payment Vuser 7:vuser7:ac76:w_id:1:payment Vuser 11:keytime:delivery:vuser11:ac79:2 secs Vuser 9:thinktime:neword:vuser9:ac57:15 secs Vuser 11:thinktime:payment:vuser11:ac30:14 secs Vuser 9:vuser9:ac57:w_id:3:ostat Vuser 11:vuser11:ac30:w_id:5:neword Vuser 9:keytime:payment:vuser9:ac3:3 secs Vuser 11:keytime:payment:vuser11:ac62:3 secs Vuser 3:keytime:payment:vuser3:ac35:3 secs Vuser 7:keytime:neword:vuser7:ac88:18 secs Vuser 11:keytime:payment:vuser11:ac96:3 secs Vuser 11:thinktime:payment:vuser11:ac47:8 secs Vuser 11:vuser11:ac47:w_id:4:neword Vuser 3:thinktime:payment:vuser3:ac24:21 secs Vuser 5:keytime:neword:vuser5:ac37:18 secs Vuser 7:keytime:payment:vuser7:ac16:3 secs Vuser 11:keytime:payment:vuser11:ac88:3 secs Vuser 3:vuser3:ac24:w_id:16:neword Vuser 11:thinktime:slev:vuser11:ac25:6 secs Vuser 11:vuser11:ac25:w_id:3:payment Vuser 5:thinktime:payment:vuser5:ac40:2 secs Vuser 5:vuser5:ac40:w_id:26:neword Vuser 5:thinktime:neword:vuser5:ac63:7 secs Vuser 5:vuser5:ac63:w_id:10:payment
One particular advantage of this type of workload is to be able to run a fixed throughput test defined by the number of Virtual Users.
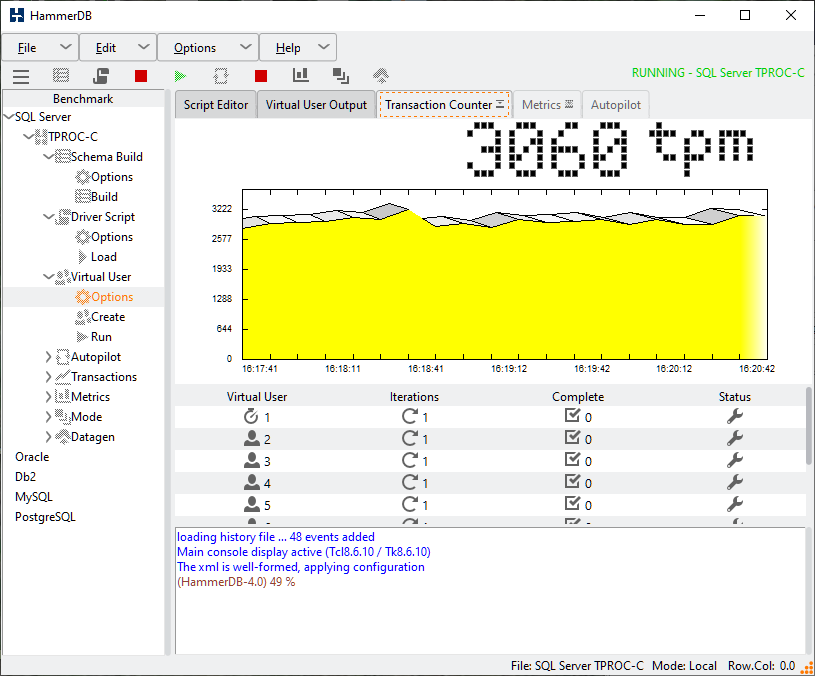
On completion of the workloads the Monitor Virtual User will report the number of Active Sessions and the performance achieved. The active Virtual Users will report when all of the asynchronous clients have completed their workloads and logged off.
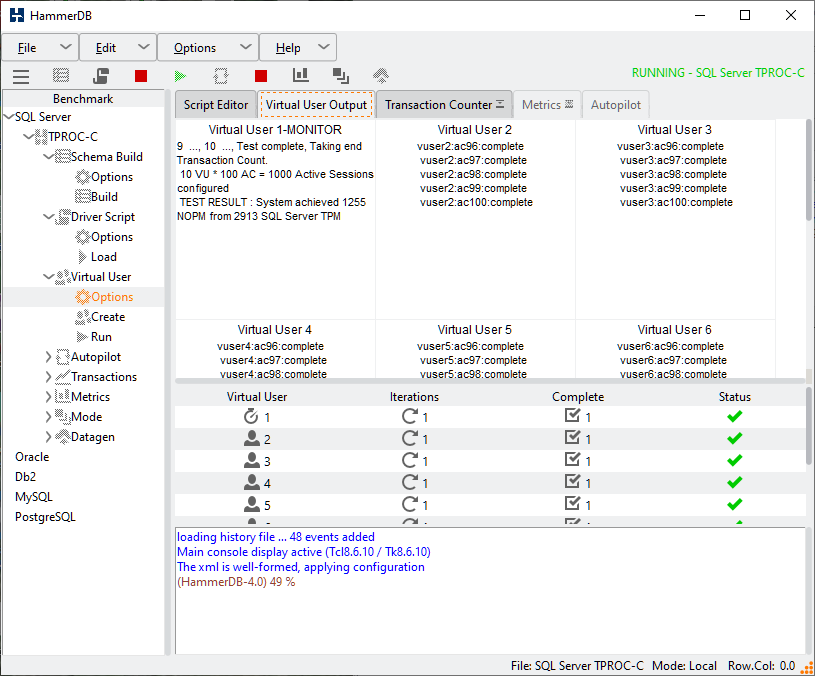
The event driven scaling feature is not intended to replace the default CPU intensive mode of testing and it is expected that this will continue to be the most popular methodology. Instead being able to increase up client sessions with keying and thinking time adds additional test scenarios for highly scalable systems and in particular is an effective test methodology for testing middle tier or proxy systems.
The XML Connect Pool is intended for simultaneously testing related multiple instances of a clustered database. It enables each Virtual User to open a pool of connections (Note that each virtual user (or asynchronous client) will open and hold all of the defined connections) and direct the individual transactions to run on a specific instance according to a pre-defined policy. With this approach it is possible for example to direct the read-write transactions to a primary instance on a cluster whilst directing the read-only transactions to the secondary.
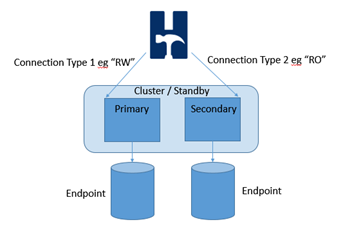
Note that for testing or evaluation of this feature it is also possible to direct one HammerDB client to test multiple separate instances at the same time provided that the instances have exactly the same warehouse count as shown in the example below. However for a valid and comparable test consistency should be ensured between the database instances. Therefore for example directing transactions against any instance in an Oracle RAC configuration would be valid as would running the read only transactions against a secondary read only instance in a cluster. However running against separate unrelated instances is possible for testing but not comparable for performance results. The monitor virtual user will continue to connect to the instance defined in the driver options and report NOPM and TPM from this standalone connection only and therefore the reliance is on the database to accurately report a cluster wide transactions and for the instances to have the same warehouse count. Nevertheless when using the XML connect pooling a client side transaction count will also be reported to provide detailed transaction data from all Virtual Users.
The configuration is defined in the database specific XML file in the config/connpool directory. It is recommended to make a backup of the file before it is modified. The XML configuration file is in 2 sections, connections and sprocs. For connections the XML configuration file should be modified according to the cluster database names with each connection defined by the tags c1, c2, c3 respectively. There is no restriction to the number of connections that you define. Under the sprocs section in the XML configuration file is defined which stored procedures will use which connections and what policy is to be used. The policy can be first_named, last_named, random or round_robin. For example with connections c1, c2 and c3 for neworder and a policy of round_robin the first neworder transaction would execute against connection c1, the second c2, the third c3, the fourth c1 and so on. For all databases and all stored procedures prepared statements are used meaning that a statement is prepared for each connection for each virtual user and a reference kept for that prepared statement for execution.
For further information on the connections opened there is a commented information line in the driver script such as #puts "sproc_cur:$st connections:[ set $cslist ] cursors:[set $cursor_list] number of cursors:[set $len] execs:[set $cnt]" prior to the opening of the standalone connection that may be uncommented for more detail when the script is run.
<connpool>
<connections>
<c1>
<mssqls_server>(local)\SQLDEVELOP</mssqls_server>
<mssqls_linux_server>host1</mssqls_linux_server>
<mssqls_tcp>false</mssqls_tcp>
<mssqls_port>1433</mssqls_port>
<mssqls_azure>false</mssqls_azure>
<mssqls_authentication>windows</mssqls_authentication>
<mssqls_linux_authent>sql</mssqls_linux_authent>
<mssqls_odbc_driver>ODBC Driver 17 for SQL Server</mssqls_odbc_driver>
<mssqls_linux_odbc>ODBC Driver 17 for SQL Server</mssqls_linux_odbc>
<mssqls_uid>sa</mssqls_uid>
<mssqls_pass>admin</mssqls_pass>
<mssqls_dbase>tpcc1</mssqls_dbase>
</c1>
<c2>
<mssqls_server>(local)\SQLDEVELOP</mssqls_server>
<mssqls_linux_server>host2</mssqls_linux_server>
<mssqls_tcp>false</mssqls_tcp>
<mssqls_port>1433</mssqls_port>
<mssqls_azure>false</mssqls_azure>
<mssqls_authentication>windows</mssqls_authentication>
<mssqls_linux_authent>sql</mssqls_linux_authent>
<mssqls_odbc_driver>ODBC Driver 17 for SQL Server</mssqls_odbc_driver>
<mssqls_linux_odbc>ODBC Driver 17 for SQL Server</mssqls_linux_odbc>
<mssqls_uid>sa</mssqls_uid>
<mssqls_pass>admin</mssqls_pass>
<mssqls_dbase>tpcc2</mssqls_dbase>
</c2>
<c3>
<mssqls_server>(local)\SQLDEVELOP</mssqls_server>
<mssqls_linux_server>host3</mssqls_linux_server>
<mssqls_tcp>false</mssqls_tcp>
<mssqls_port>1433</mssqls_port>
<mssqls_azure>false</mssqls_azure>
<mssqls_authentication>windows</mssqls_authentication>
<mssqls_linux_authent>sql</mssqls_linux_authent>
<mssqls_odbc_driver>ODBC Driver 17 for SQL Server</mssqls_odbc_driver>
<mssqls_linux_odbc>ODBC Driver 17 for SQL Server</mssqls_linux_odbc>
<mssqls_uid>sa</mssqls_uid>
<mssqls_pass>admin</mssqls_pass>
<mssqls_dbase>tpcc3</mssqls_dbase>
</c3>
</connections>
<sprocs>
<neworder>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</neworder>
<payment>
<connections>c1 c2</connections>
<policy>first_named</policy>
</payment>
<delivery>
<connections>c2 c3</connections>
<policy>last_named</policy>
</delivery>
<stocklevel>
<connections>c1 c2 c3</connections>
<policy>random</policy>
</stocklevel>
<orderstatus>
<connections>c2 c3</connections>
<policy>round_robin</policy>
</orderstatus>
</sprocs>
</connpool>
After modifying the XML configuration file select XML Connect Pool in the Driver Options to activate this feature.
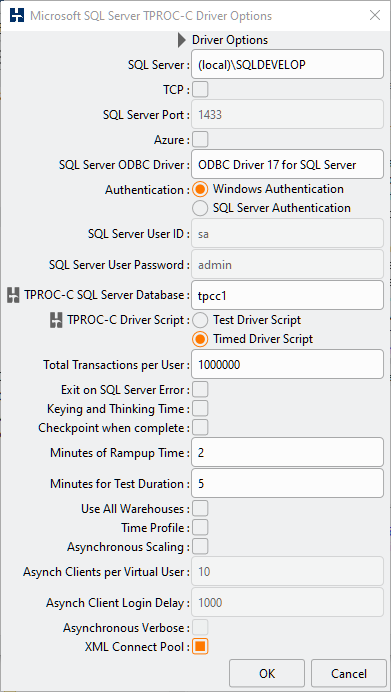
For this example the additional information for the comments is also added to illustrate the connections made.

When the Virtual Users are run the logfile shows that connections are made for the active Virtual Users according to the connections and policies defined in the XML configuration file. Also prepared statements are created and held in a pool for execution against the defined policy. Also note that the standalone connection "tpcc1" is also made to monitor the transaction rates and define the warehouse count for the run.
Vuser 2:sproc_cur:neword_st connections:{odbcc1 odbcc2 odbcc3} cursors:::oo::Obj23::Stmt::3 ::oo::Obj28::Stmt::3 ::oo::Obj33::Stmt::3 number of cursors:3 execs:0
Vuser 2:sproc_cur:payment_st connections:{odbcc1 odbcc2} cursors:::oo::Obj23::Stmt::4 ::oo::Obj28::Stmt::4 number of cursors:2 execs:0
Vuser 2:sproc_cur:ostat_st connections:{odbcc2 odbcc3} cursors:::oo::Obj28::Stmt::5 ::oo::Obj33::Stmt::4 number of cursors:2 execs:0
Vuser 2:sproc_cur:delivery_st connections:{odbcc1 odbcc2 odbcc3} cursors:::oo::Obj23::Stmt::5 ::oo::Obj28::Stmt::6 ::oo::Obj33::Stmt::5 number of cursors:3 execs:0
Vuser 2:sproc_cur:slev_st connections:{odbcc2 odbcc3} cursors:::oo::Obj28::Stmt::7 ::oo::Obj33::Stmt::6 number of cursors:2 execs:0
Vuser 3:sproc_cur:neword_st connections:{odbcc1 odbcc2 odbcc3} cursors:::oo::Obj23::Stmt::3 ::oo::Obj28::Stmt::3 ::oo::Obj33::Stmt::3 number of cursors:3 execs:0
Vuser 3:sproc_cur:payment_st connections:{odbcc1 odbcc2} cursors:::oo::Obj23::Stmt::4 ::oo::Obj28::Stmt::4 number of cursors:2 execs:0
Vuser 3:sproc_cur:ostat_st connections:{odbcc2 odbcc3} cursors:::oo::Obj28::Stmt::5 ::oo::Obj33::Stmt::4 number of cursors:2 execs:0
Vuser 3:sproc_cur:delivery_st connections:{odbcc1 odbcc2 odbcc3} cursors:::oo::Obj23::Stmt::5 ::oo::Obj28::Stmt::6 ::oo::Obj33::Stmt::5 number of cursors:3 execs:0
Vuser 3:sproc_cur:slev_st connections:{odbcc2 odbcc3} cursors:::oo::Obj28::Stmt::7 ::oo::Obj33::Stmt::6 number of cursors:2 execs:0On completion of the run the NOPM and TPM is recorded. This is the area where it is of particular importance to be aware of the database and cluster configuration for the results to be consistent. It is therefore valid to reiterate that if the cluster and standalone connection does not record all of the transactions in the cluster then the NOPM results will only be returned for the standalone connection. By way of example in the test configuration shown there are 3 separate databases and the standalone connection is made to tpcc1. Therefore the test results shows the NOPM value at approximately 1/3rd of the ratio expected against the TPM value that records all of the transactions against the SQL Server. For this reason the CLIENT SIDE TPM is also shown. In this example the neworder value per minute is 78319 a close equivalent to 3 x 26207 and therefore gives an indication of the NOPM value for multiple instances in a non-cluster configuration. In this case 3 connections were made to tpcc1, tpcc2 and tpcc3 and the connections chosen to round robin between them, therefore the actual number of NOPM is 3X that recorded from just the standalone connection. In a correctly configured cluster environment it would be the same and the results wouyld be both consistent and valid. Be aware that these client side values are recorded during both rampup and timed test periods and therefore may not accurately reflect the results from a valid timed test.
Vuser 1:2 Active Virtual Users configured Vuser 1:TEST RESULT : System achieved 26207 NOPM from 180515 SQL Server TPM Vuser 1:CLIENT SIDE TPM : neworder 78319 payment 78185 delivery 7855 stocklevel 7826 orderstatus 7809
In addition to the CLIENT SIDE TPM each Virtual User will also report the total number of transactions that it processed from the time that it started running to the end of the test.
Vuser 2:VU2 processed neworder 275335 payment 273822 delivery 27495 stocklevel 27588 orderstatus 27568 transactions Vuser 3:VU3 processed neworder 272901 payment 273475 delivery 27493 stocklevel 27194 orderstatus 27097 transactions
The XML Connect Pool feature provides advanced features for the expert user to test clusters and multiple instances simultaneously, it also gives the user a high degree of control on how this is used, therefore it is at the users discretion to use these settings appropriately to ensure consistent results.