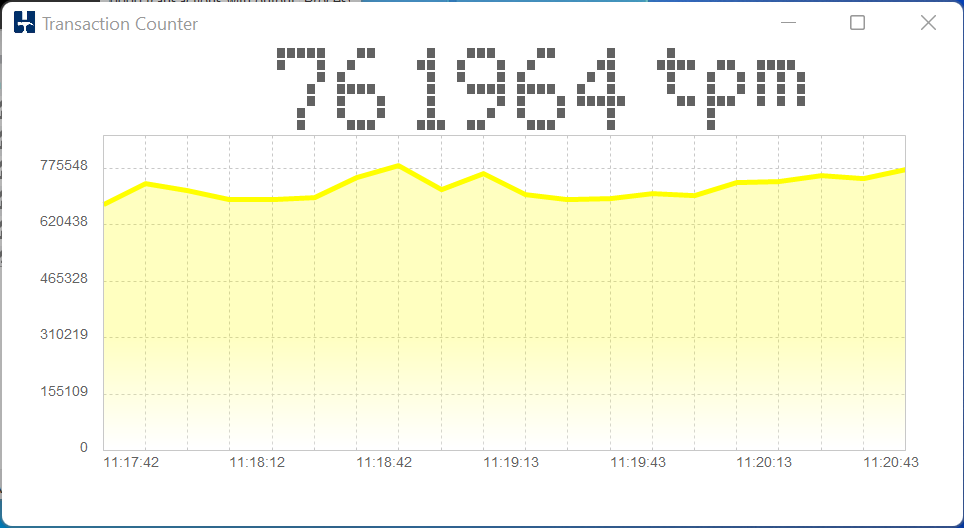
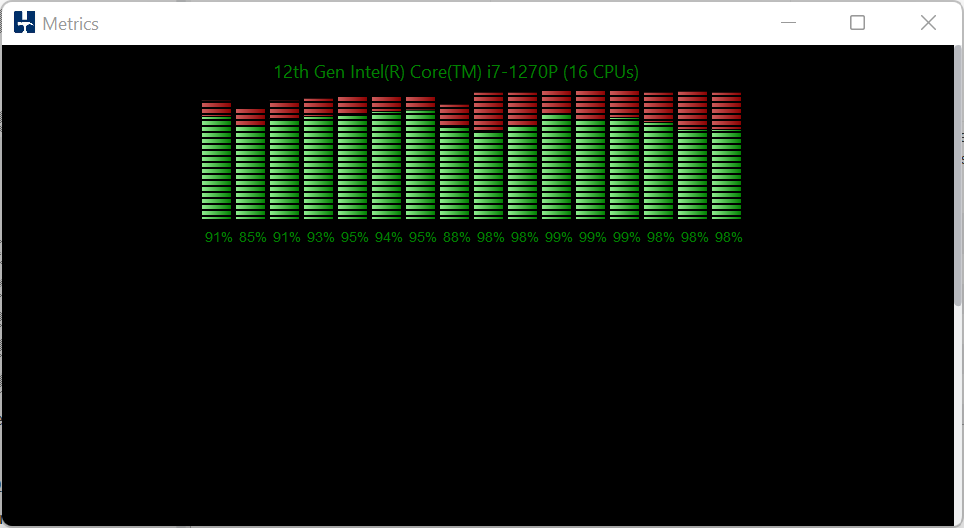
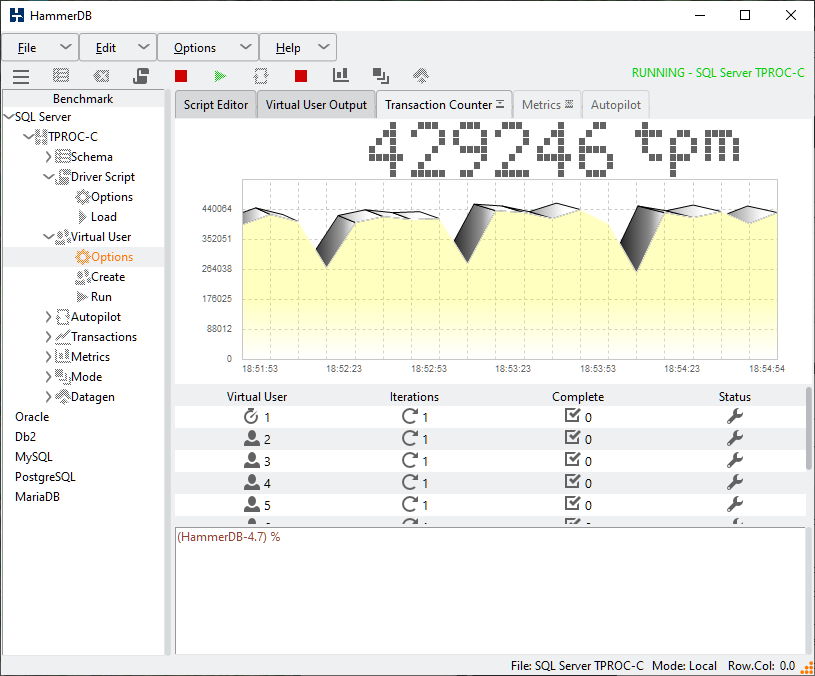
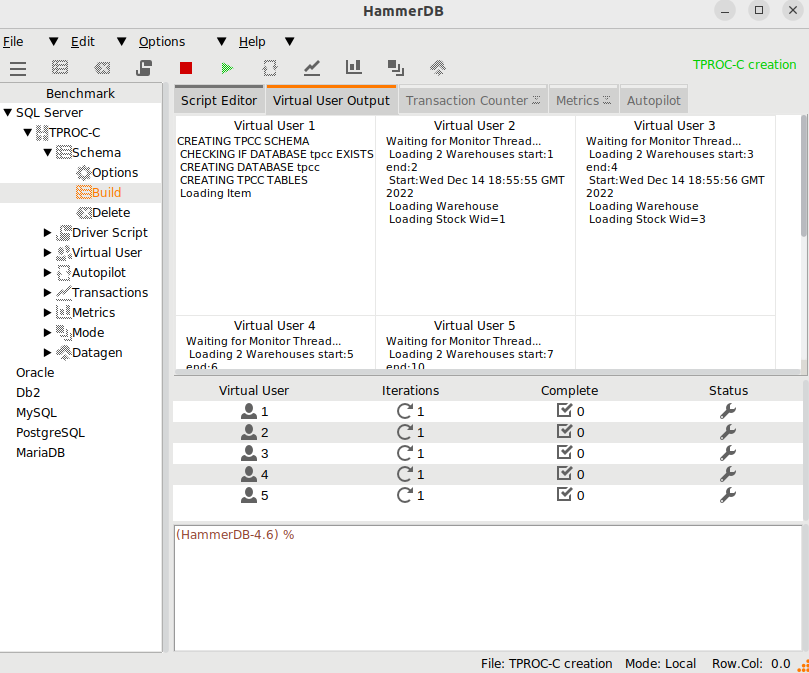
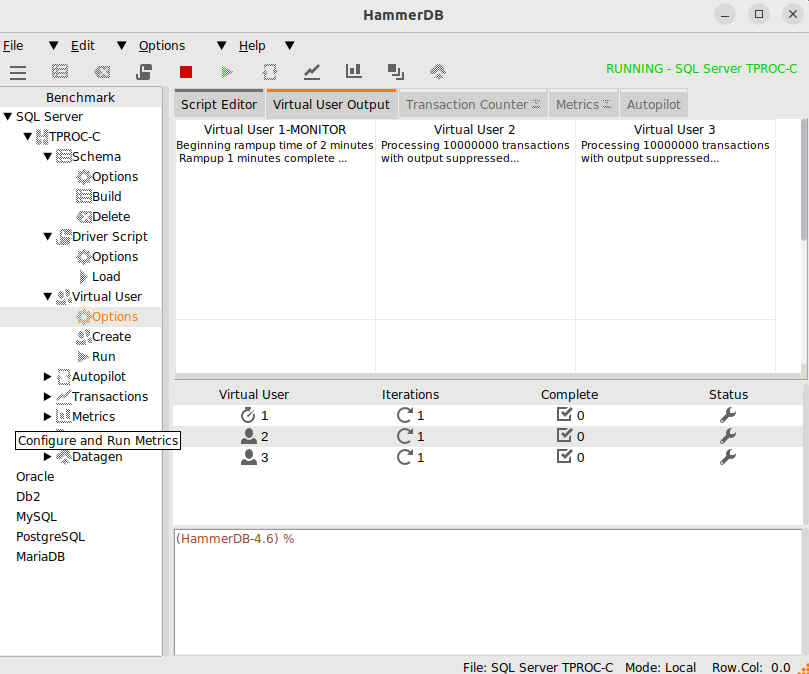
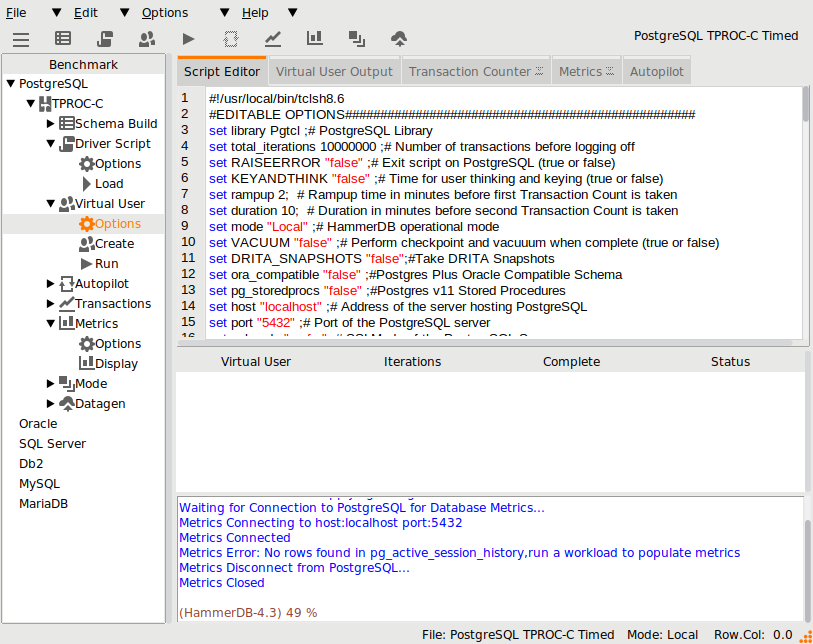
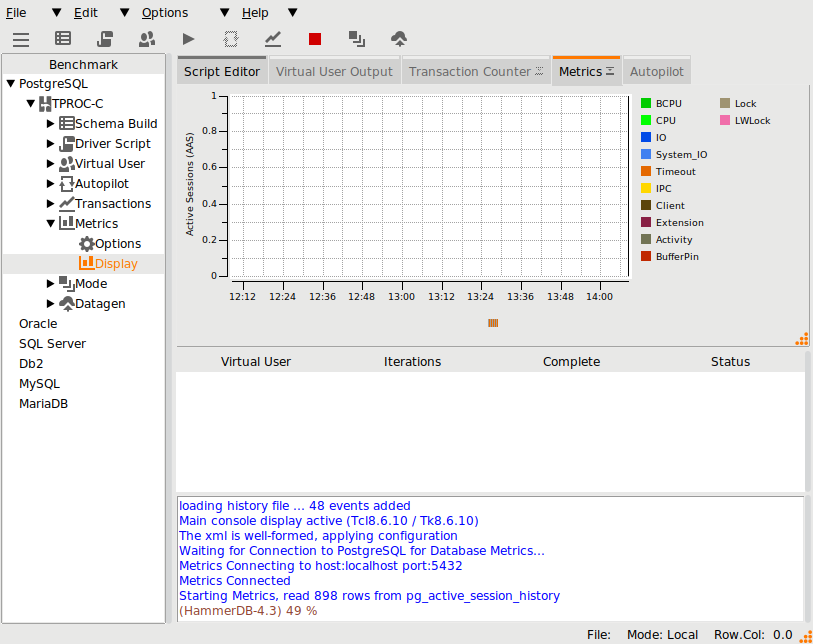
In HammerDB v4.7 the Transaction Counter and CPU Metrics have been updated on both Windows and Linux to use a package called tkpath enabling more advanced graphic features using the GPU where available. This gives the transaction counter,
and CPU metrics,
a more updated look and feel, whilst maintaining the previous lightweight impact of the graphical code.
On Linux HammerDB GUI requires Cairo Graphics installed to support this functionality. On all Linux systems tested Cairo Graphics was already installed, however if not it can be installed as follows:
The transaction counter can be dragged out from the tab in the notebook as shown previously to display in a separate window, or left in the main window as shown below:
The embedded counter will now also resize when the main window is resized, so when doing demos and filling the screen with HammerDB, the transaction counter will now fill the available space.
The previous ribbon type effect has been deprecated for a more updated look. However, if there is a desire to maintain the previous graph, it can be enabled in the XML configuration file before HammerDB is started by setting the value tc_graph_ribbon to true from the default of false.
Note that the XML must be set before the first start, as after this point the parameters are stored in the SQLite files and therefore it will be necessary to remove/refresh the SQLite parameter files to pick up any subsequent changes. When this is done, the previous ribbon effect is shown, although updated to use tkpath features such as antialiasing.
In this post, we will do a walk through example of installing and configuring unixODBC and the SQL Server on Linux drivers as well as the HammerDB connection options to enable HammerDB on Linux to be able to connect to SQL Server. In the example, we have SQL Server running on Windows and are using a virtualized Linux instance to run HammerDB to connect to SQL Server.
unixODBC
Firstly get unixODBC from here http://www.unixodbc.org/ and configure making sure the that the –enable-fastvalidate option is given. In this example, we install in the /usr/local directory using the command make and make install after configure.
Then install the Microsoft ODBC Drivers using the instructions here. Once installed, we will see the drivers successfully installed and find the dependent libraries we need.
root@REDPOLL:/usr/local/unixODBC/etc# more odbcinst.ini
[ODBC Driver 17 for SQL Server]
Description=Microsoft ODBC Driver 17 for SQL Server
Driver=/opt/microsoft/msodbcsql17/lib64/libmsodbcsql-17.10.so.2.1
UsageCount=1
[ODBC Driver 18 for SQL Server]
Description=Microsoft ODBC Driver 18 for SQL Server
Driver=/opt/microsoft/msodbcsql18/lib64/libmsodbcsql-18.1.so.2.1
UsageCount=1
We can verify the configuration and drivers as follows:
hammerdb@REDPOLL:~$ more .bash_profile
export PATH="$PATH:/opt/mssql-tools/bin"
export PATH=:/usr/local/unixODBC/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/unixODBC/lib:$LD_LIBRARY_PATH
export ODBCSYSINI=/usr/local/unixODBC/etc
export ODBCINI=/usr/local/unixODBC/etc/odbc.ini
hammerdb@REDPOLL:~$ odbcinst -d -q
[ODBC Driver 17 for SQL Server]
[ODBC Driver 18 for SQL Server]
Test Connectivity
In this example, as we are running HammerDB for Linux in a VM to connect back to the Windows host we need to either configure or temporarily disable Defender Firewall to allow HammerDB to connect to SQL Server.
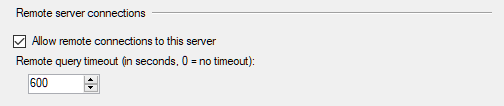
And also enable remote connections to SQL Server from SSMS.
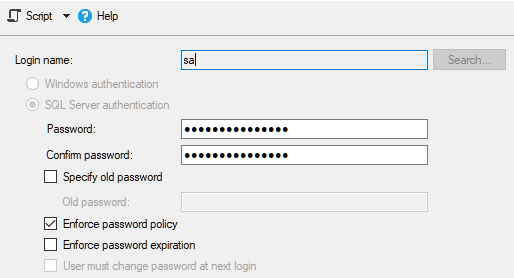
We also need to use SQL Server Authentication, and set a password for the sa user.
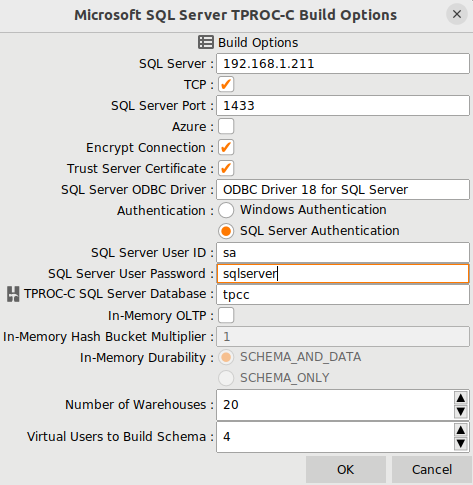
And configure HammerDB to connect from Linux to Windows, and therefore we set the TCP check option as well as using the SQL Server authentication with the user and password we set previously.
Build Schema
We can now run HammerDB to verify that we can connect to SQL Server from our Linux client.
Run Test
We the build is complete, we can begin running a test from our SQL Server on Linux client.
And confirm that our Linux host has connected and is running the workload on SQL Server.
Summary
In this post, we have shown how to configure the ODBC Drivers for SQL Server on Linux for HammerDB. When the test complete, do not forget to re-enable Windows Firewall if you disabled it.
The TPC publishes an official Docker image on Docker Hub to enable the rapid deployment and testing of databases with HammerDB. This image includes example scripts to build schemas and test your databases with a single command.
In this post, we will show an example of using Docker to deploy the HammerDB command line and test a database with minimal effort. Our Linux test system is running a MariaDB 10.10 database with Docker installed, so we are going to use Docker to pull the HammerDB image and run the test scripts to measure the database performance.
Docker Hub
The image can be found on Docker Hub under the tpcorg account.
Docker Pull
On a system with docker installed, use docker pull tpcorg/hammerdb to pull the latest image.
root@REDPOLL:/home/hammerdb/HammerDB-4.6# ./hammerdbcli
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized new SQLite on-disk database /tmp/hammer.DB
hammerdb>librarycheck
Checking database library for Oracle
Success ... loaded library Oratcl for Oracle
Checking database library for MSSQLServer
Success ... loaded library tdbc::odbc for MSSQLServer
Checking database library for Db2
Error: failed to load db2tcl - couldn't load file "/home/hammerdb/HammerDB-4.6/lib/db2tcl2.0.1/libdb2tcl.so": libdb2.so.1: cannot open shared object file: No such file or directory
Ensure that Db2 client libraries are installed and the location in the LD_LIBRARY_PATH environment variable
Checking database library for MySQL
Success ... loaded library mysqltcl for MySQL
Checking database library for PostgreSQL
Success ... loaded library Pgtcl for PostgreSQL
Checking database library for MariaDB
Success ... loaded library mariatcl for MariaDB
Database Configuration
We have run Docker to enable to access the host network so we start the MariaDB on the host with the host bind_address (in this case the system name is redpoll) and the default port of 3306 and start the database.
We can check on the host the IP address of the Docker container, in this case 172.17.0.1 and allow access to HammerDB from the container as the root user.
root@REDPOLL:/home/hammerdb/mariadb-10.10.2-linux-systemd-x86_64# ip addr show docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:a7:d9:56:a9 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
MariaDB [(none)]> select password('maria');
+-------------------------------------------+
| password('maria') |
+-------------------------------------------+
| *8061C323A725701555411A7E18421F077A840CD7 |
+-------------------------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> create user 'root'@'172.17.0.1' identified by password '*8061C323A725701555411A7E18421F077A840CD7';
Query OK, 0 rows affected (0.002 sec)
MariaDB [(none)]>
Script Configuration
Under the HammerDB home directory is a scripts directory containing example scripts to test all supported databases except for Db2 in both tcl and python format for both TPROC-C and TPROC-H workloads. There is a driver script that can be used to build, test, delete and query the results of a workload with a single script. The scripts are available in both Python and Tcl formats.
root@REDPOLL:/home/hammerdb/HammerDB-4.6# ls -ltR scripts/
scripts/:
total 8
drwxr-xr-x 8 root root 4096 Dec 13 22:31 python
drwxr-xr-x 8 root root 4096 Dec 13 22:31 tcl
scripts/python:
total 24
drwxr-xr-x 2 root root 4096 Dec 13 22:31 generic
drwxr-xr-x 4 root root 4096 Dec 13 22:31 maria
drwxr-xr-x 4 root root 4096 Dec 13 22:31 mssqls
drwxr-xr-x 4 root root 4096 Dec 13 22:31 mysql
drwxr-xr-x 4 root root 4096 Dec 13 22:31 oracle
drwxr-xr-x 4 root root 4096 Dec 13 22:31 postgres
root@REDPOLL:/home/hammerdb/HammerDB-4.6/scripts/tcl/maria/tprocc# ls
maria_tprocc.sh
maria_tprocc_deleteschema.tcl
maria_tprocc_run.tcl
maria_tprocc_buildschema.tcl
maria_tprocc_result.tcl
Update the scripts to be used with the connection settings for the database to be tested. In this case, the MariaDB database is running on port 3306 on host redpoll. The socket will not be used as the hostname specified is not “localhost”. The connection parameters for all scripts is all we need to change.
We can now run the main driver script from the HammerDB home directory to build the schema, run the test, delete the schema and then print the results of the test as follows:
root@REDPOLL:/home/hammerdb/HammerDB-4.6# ./scripts/tcl/maria/tprocc/maria_tprocc.sh
BUILD HAMMERDB SCHEMA
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/hammerdb/HammerDB-4.6/TMP/hammer.DB using existing tables (229,376 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
Value redpoll for connection:maria_host is the same as existing value redpoll, no change made
Value 3306 for connection:maria_port is the same as existing value 3306, no change made
Value /tmp/mariadb.sock for connection:maria_socket is the same as existing value /tmp/mariadb.sock, no change made
Value 20 for tpcc:maria_count_ware is the same as existing value 20, no change made
Value 4 for tpcc:maria_num_vu is the same as existing value 4, no change made
Value root for tpcc:maria_user is the same as existing value root, no change made
Value maria for tpcc:maria_pass is the same as existing value maria, no change made
Value tpcc for tpcc:maria_dbase is the same as existing value tpcc, no change made
Value innodb for tpcc:maria_storage_engine is the same as existing value innodb, no change made
Value false for tpcc:maria_partition is the same as existing value false, no change made
SCHEMA BUILD STARTED
Script cleared
Building 20 Warehouses with 5 Virtual Users, 4 active + 1 Monitor VU(dict value maria_num_vu is set to 4)
Ready to create a 20 Warehouse MariaDB TPROC-C schema
in host REDPOLL:3306 under user ROOT in database TPCC with storage engine INNODB?
Enter yes or no: replied yes
Vuser 1 created - WAIT IDLE
Vuser 2 created - WAIT IDLE
Vuser 3 created - WAIT IDLE
Vuser 4 created - WAIT IDLE
Vuser 5 created - WAIT IDLE
Vuser 1:RUNNING
Vuser 1:Monitor Thread
Vuser 1:CREATING TPCC SCHEMA
Vuser 1:Ssl_cipher
Vuser 1:CREATING DATABASE tpcc
Vuser 1:CREATING TPCC TABLES
Vuser 1:Loading Item
Vuser 2:RUNNING
Vuser 2:Worker Thread
Vuser 2:Waiting for Monitor Thread...
Vuser 2:Ssl_cipher
Vuser 2:Loading 5 Warehouses start:1 end:5
Vuser 2:Start:Wed Dec 14 13:47:59 +0000 2022
Vuser 2:Loading Warehouse
Vuser 2:Loading Stock Wid=1
Vuser 3:RUNNING
Vuser 3:Worker Thread
Vuser 3:Waiting for Monitor Thread...
Vuser 3:Ssl_cipher
Vuser 3:Loading 5 Warehouses start:6 end:10
Vuser 5:Loading Warehouse
Vuser 5:Loading Stock Wid=16
...
Vuser 2:FINISHED SUCCESS
Vuser 3:...2000
Vuser 3:...3000
Vuser 3:Orders Done
Vuser 3:End:Wed Dec 14 13:51:05 +0000 2022
Vuser 3:FINISHED SUCCESS
Vuser 1:Workers: 0 Active 4 Done
Vuser 1:CREATING TPCC STORED PROCEDURES
Vuser 1:GATHERING SCHEMA STATISTICS
Vuser 1:TPCC SCHEMA COMPLETE
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
SCHEMA BUILD COMPLETED
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
RUN HAMMERDB TEST
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/hammerdb/HammerDB-4.6/TMP/hammer.DB using existing tables (372,736 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
Value redpoll for connection:maria_host is the same as existing value redpoll, no change made
Value 3306 for connection:maria_port is the same as existing value 3306, no change made
Value /tmp/mariadb.sock for connection:maria_socket is the same as existing value /tmp/mariadb.sock, no change made
Value root for tpcc:maria_user is the same as existing value root, no change made
Value maria for tpcc:maria_pass is the same as existing value maria, no change made
Value tpcc for tpcc:maria_dbase is the same as existing value tpcc, no change made
Value timed for tpcc:maria_driver is the same as existing value timed, no change made
Value 2 for tpcc:maria_rampup is the same as existing value 2, no change made
Value 5 for tpcc:maria_duration is the same as existing value 5, no change made
Value true for tpcc:maria_allwarehouse is the same as existing value true, no change made
Value true for tpcc:maria_timeprofile is the same as existing value true, no change made
Script loaded, Type "print script" to view
TEST STARTED
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Vuser 3 created - WAIT IDLE
Vuser 4 created - WAIT IDLE
Vuser 5 created - WAIT IDLE
5 Virtual Users Created with Monitor VU
Transaction Counter Started
Transaction Counter thread running with threadid:tid0x7fec51ffb700
0 MariaDB tpm
Vuser 1:RUNNING
Vuser 1:Initializing xtprof time profiler
Vuser 1:Ssl_cipher
Vuser 1:Beginning rampup time of 2 minutes
Vuser 2:RUNNING
Vuser 2:Initializing xtprof time profiler
Vuser 3:RUNNING
Vuser 2:Ssl_cipher
Vuser 3:Initializing xtprof time profiler
Vuser 2:VU 2 : Assigning WID=1 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 3:Ssl_cipher
Vuser 2:VU 2 : Assigning WID=5 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 3:VU 3 : Assigning WID=2 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 2:VU 2 : Assigning WID=9 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 3:VU 3 : Assigning WID=6 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 2:VU 2 : Assigning WID=13 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 3:VU 3 : Assigning WID=10 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 2:VU 2 : Assigning WID=17 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 3:VU 3 : Assigning WID=14 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 2:Processing 10000000 transactions with output suppressed...
Vuser 3:VU 3 : Assigning WID=18 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 3:Processing 10000000 transactions with output suppressed...
Vuser 4:RUNNING
Vuser 4:Initializing xtprof time profiler
Vuser 4:Ssl_cipher
Vuser 4:VU 4 : Assigning WID=3 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 4:VU 4 : Assigning WID=7 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 4:VU 4 : Assigning WID=11 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 4:VU 4 : Assigning WID=15 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 4:VU 4 : Assigning WID=19 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 4:Processing 10000000 transactions with output suppressed...
Vuser 5:RUNNING
Vuser 5:Initializing xtprof time profiler
Vuser 5:Ssl_cipher
Vuser 5:VU 5 : Assigning WID=4 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 5:VU 5 : Assigning WID=8 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 5:VU 5 : Assigning WID=12 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 5:VU 5 : Assigning WID=16 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 5:VU 5 : Assigning WID=20 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 5:Processing 10000000 transactions with output suppressed...
54690 MariaDB tpm
86406 MariaDB tpm
63144 MariaDB tpm
55824 MariaDB tpm
90012 MariaDB tpm
Vuser 1:Rampup 1 minutes complete ...
90228 MariaDB tpm
93984 MariaDB tpm
79008 MariaDB tpm
67278 MariaDB tpm
62952 MariaDB tpm
93834 MariaDB tpm
107478 MariaDB tpm
Vuser 1:Rampup 2 minutes complete ...
Vuser 1:Rampup complete, Taking start Transaction Count.
Vuser 1:Timing test period of 5 in minutes
104154 MariaDB tpm
95004 MariaDB tpm
82794 MariaDB tpm
83328 MariaDB tpm
74424 MariaDB tpm
43962 MariaDB tpm
Vuser 1:1 ...,
105270 MariaDB tpm
37362 MariaDB tpm
12816 MariaDB tpm
5304 MariaDB tpm
10470 MariaDB tpm
6084 MariaDB tpm
Vuser 1:2 ...,
5730 MariaDB tpm
6048 MariaDB tpm
6768 MariaDB tpm
9438 MariaDB tpm
11280 MariaDB tpm
10428 MariaDB tpm
Vuser 1:3 ...,
17022 MariaDB tpm
14310 MariaDB tpm
19374 MariaDB tpm
22326 MariaDB tpm
16698 MariaDB tpm
20100 MariaDB tpm
21000 MariaDB tpm
Vuser 1:4 ...,
10902 MariaDB tpm
14898 MariaDB tpm
60228 MariaDB tpm
37632 MariaDB tpm
50778 MariaDB tpm
34044 MariaDB tpm
Vuser 1:5 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:4 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 15199 NOPM from 35354 MariaDB TPM
Vuser 1:Gathering timing data from Active Virtual Users...
48096 MariaDB tpm
Vuser 5:FINISHED SUCCESS
Vuser 2:FINISHED SUCCESS
Vuser 3:FINISHED SUCCESS
Vuser 4:FINISHED SUCCESS
Vuser 1:Calculating timings...
8226 MariaDB tpm
Vuser 1:Writing timing data to /home/hammerdb/HammerDB-4.6/TMP/hdbxtprofile.log
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
0 MariaDB tpm
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
0 MariaDB tpm
vudestroy success
Transaction Counter thread running with threadid:tid0x7fec51ffb700
Stopping Transaction Counter
TEST COMPLETE
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
DROP HAMMERDB SCHEMA
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/hammerdb/HammerDB-4.6/TMP/hammer.DB using existing tables (397,312 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
Value redpoll for connection:maria_host is the same as existing value redpoll, no change made
Value 3306 for connection:maria_port is the same as existing value 3306, no change made
Value /tmp/mariadb.sock for connection:maria_socket is the same as existing value /tmp/mariadb.sock, no change made
Value root for tpcc:maria_user is the same as existing value root, no change made
Value maria for tpcc:maria_pass is the same as existing value maria, no change made
Value tpcc for tpcc:maria_dbase is the same as existing value tpcc, no change made
DROP SCHEMA STARTED
Script cleared
Deleting schema with 1 Virtual User
Do you want to delete the TPCC TPROC-C schema
in host REDPOLL:3306 under user ROOT?
Enter yes or no: replied yes
Vuser 1 created - WAIT IDLE
Vuser 1:RUNNING
Vuser 1:Ssl_cipher
DROP SCHEMA COMPLETED
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HAMMERDB RESULT
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/hammerdb/HammerDB-4.6/TMP/hammer.DB using existing tables (397,312 KB)
TRANSACTION RESPONSE TIMES
{
"DELIVERY": {
"elapsed_ms": "439561.0",
"calls": "3320",
"min_ms": "4.383",
"avg_ms": "59.972",
"max_ms": "77608.65",
"total_ms": "199106.945",
"p99_ms": "307.374",
"p95_ms": "10.461",
"p50_ms": "5.74",
"sd": "1684200.807",
"ratio_pct": "45.476"
},
"NEWORD": {
"elapsed_ms": "439561.0",
"calls": "33945",
"min_ms": "1.227",
"avg_ms": "5.016",
"max_ms": "17419.641",
"total_ms": "170261.191",
"p99_ms": "8.509",
"p95_ms": "4.596",
"p50_ms": "2.503",
"sd": "105049.036",
"ratio_pct": "38.888"
},
"PAYMENT": {
"elapsed_ms": "439561.0",
"calls": "33696",
"min_ms": "0.602",
"avg_ms": "1.512",
"max_ms": "2687.342",
"total_ms": "50964.941",
"p99_ms": "3.443",
"p95_ms": "1.773",
"p50_ms": "1.004",
"sd": "23559.832",
"ratio_pct": "11.64"
},
"OSTAT": {
"elapsed_ms": "439561.0",
"calls": "3393",
"min_ms": "0.454",
"avg_ms": "3.023",
"max_ms": "1321.03",
"total_ms": "10255.874",
"p99_ms": "3.218",
"p95_ms": "1.519",
"p50_ms": "0.868",
"sd": "44465.804",
"ratio_pct": "2.342"
},
"SLEV": {
"elapsed_ms": "439561.0",
"calls": "3310",
"min_ms": "0.82",
"avg_ms": "1.352",
"max_ms": "184.051",
"total_ms": "4476.381",
"p99_ms": "3.524",
"p95_ms": "1.995",
"p50_ms": "1.135",
"sd": "3229.144",
"ratio_pct": "1.022"
}
}
TRANSACTION COUNT
{"MariaDB tpm": {
"0": "2022-12-14 14:00:23",
"54690": "2022-12-14 13:51:19",
"86406": "2022-12-14 13:51:29",
"63144": "2022-12-14 13:51:39",
"55824": "2022-12-14 13:51:49",
"90012": "2022-12-14 13:51:59",
"90228": "2022-12-14 13:52:10",
"93984": "2022-12-14 13:52:19",
"79008": "2022-12-14 13:52:29",
"67278": "2022-12-14 13:52:39",
"62952": "2022-12-14 13:52:49",
"93834": "2022-12-14 13:52:59",
"107478": "2022-12-14 13:53:09",
"104154": "2022-12-14 13:53:19",
"95004": "2022-12-14 13:53:29",
"82794": "2022-12-14 13:53:39",
"83328": "2022-12-14 13:53:49",
"74424": "2022-12-14 13:53:59",
"43962": "2022-12-14 13:54:09",
"105270": "2022-12-14 13:54:19",
"37362": "2022-12-14 13:54:29",
"12816": "2022-12-14 13:54:39",
"5304": "2022-12-14 13:54:49",
"10470": "2022-12-14 13:54:59",
"6084": "2022-12-14 13:55:09",
"5730": "2022-12-14 13:55:19",
"6048": "2022-12-14 13:55:29",
"6768": "2022-12-14 13:55:39",
"9438": "2022-12-14 13:55:49",
"11280": "2022-12-14 13:56:00",
"10428": "2022-12-14 13:56:10",
"17022": "2022-12-14 13:56:22",
"14310": "2022-12-14 13:56:30",
"19374": "2022-12-14 13:56:40",
"22326": "2022-12-14 13:56:50",
"16698": "2022-12-14 13:57:00",
"20100": "2022-12-14 13:57:10",
"21000": "2022-12-14 13:57:20",
"10902": "2022-12-14 13:57:30",
"14898": "2022-12-14 13:57:40",
"60228": "2022-12-14 13:57:50",
"37632": "2022-12-14 13:58:00",
"50778": "2022-12-14 13:58:10",
"34044": "2022-12-14 13:58:20",
"48096": "2022-12-14 13:58:32",
"8226": "2022-12-14 13:58:45"
}}
HAMMERDB RESULT
[
"6399D4CD5EFC03E233239383",
"2022-12-14 13:51:09",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 15199 NOPM from 35354 MariaDB TPM"
]
Note that we captured the job timings, transaction count and test result at the end of the test.
Results storage
HammerDB will export a TMP directory in the HammerDB home directory for the storage of configuration databases and a text output of results.
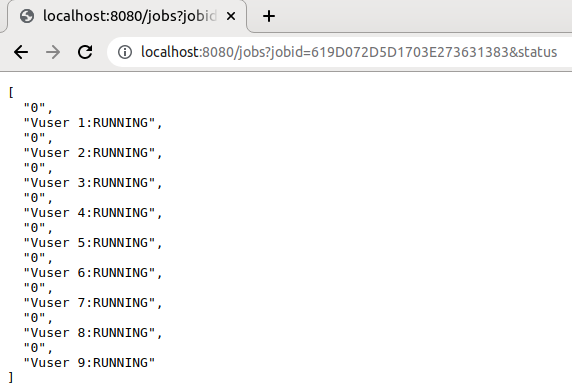
hammerdb>job "6399D4CD5EFC03E233239383" result
[
"6399D4CD5EFC03E233239383",
"2022-12-14 13:51:09",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 15199 NOPM from 35354 MariaDB TPM"
]
Stopping and Starting Docker
Use the Docker, stop, start and attach commands to run the HammerDB container when required.
In this post we have used the offical HammerDB docker container from tpcorg to rapidly deploy HammerDB and run the included example scripts to gain an insight into database performance on our host system. You can also run HammerDB interactively or with your own scripts to gain further insight.
Feedback from the Community raised the Issue Adding the enhancement for storing and retrieval of HammerDB results and configurations#352 that although HammerDB prints result output interactively and to log files, it would be preferred to have these results stored in a format that could be browsed at a later point. In particular, after a running a test it would be ideal to have a repository where we could verify the configuration of the workload that was run, the results and any timing or transaction count data generated to bring all the log output into a central location. HammerDB v4.6 does this with the “jobs” command.
Jobs Configuration and Storage
The base configuration for the jobs storage can be found in the generic.xml file in the commandline section.
The default storage location is set to “TMP” where HammerDB will firstly check to see if a TMP or TEMP environment variable has been set and if not find a default temp location and either create a SQLite database called hammer.DB if one does not already exist in this location or open the existing one. For example on Windows an example of opening a new database.
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized new SQLite on-disk database C:/Users/Hdb/AppData/Local/Temp/hammer.DB
hammerdb>
and on Linux for opening a new database where we have set the TMP environment variable to a new directory called TMP under the HammerDB-4.6 directory.
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/hdb/HammerDB-4.6/TMP/hammer.DB using existing tables (36,864 KB)
hammerdb>
If for any reason you wish to completely refresh all jobs data it is safe to remove the hammer.DB file and it will be recreated on the next restart. The options for jobs output and disabling jobs can be set at runtime.
An additional option is given in the timeprofile section called xt_job_storage, where if using the xt time profiler it will enable/disable the storage of the time profile data.
By default, the jobs storage is disabled in the GUI for v4.6, however advanced users can fully enable it by modifying the following sections in the jobs and xtprof modules respectively with the output from the GUI queryable from the CLI at this release.
proc init_job_tables_gui { } {
#In the GUI, we disable the jobs output even though it works by running the jobs command in the console
rename jobs {}
uplevel #0 {proc hdbjobs { args } { return "" }}
#If we want to enable jobs output in the GUI comment out previous 2 lines and uncomment the following line
#init_job_tables
}
To enable the time profiling in the GUI in the xtprof module update the following:
#If running in the GUI do not try to store output in SQLite
if { [ tsv::exists commandline sqldb ] eq 0 } {
set xtjob_storage 0
}
Disabling Jobs
If the storage of job related data is not desired, then it is possible to disable/enable this feature with the jobs disable command.
hammerdb>jobs disable 1
Disabling jobs repository, restart HammerDB to take effect
hammerdb>jobs disable 0
Enabling jobs repository, restart HammerDB to take effect
If disabled, the SQLite repository database is not opened, and it is not possible to query any jobs related data. Doing so will prompt on how to re-enable the feature. When enabled, the repository will be opened and it will be possible to query the data previously stored.
$ ./hammerdbcli
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
hammerdb>jobs
Error: Jobs Disabled: enable with command "jobs disable 0" and restart HammerDB
$ ./hammerdbcli
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.6/TMP/hammer.DB using existing tables (36,864 KB)
hammerdb>
Creating Jobs and Formatting Output
When enabled, a job will be created with a unique id whenever a workload is run. This happens for both a schema build and running a test.
For example, we will run the following script to build a TPROC-C schema
After running the scripts using the jobs command we can now see that we have created 2 jobs. One for building the schema and one for running the test as expected.
For querying a build, the status command will show whether all Virtual Users started and finished successfully, allowing a quick way to check the status of a build.
hammerdb>job format JSON
Setting jobs output format to json
hammerdb>jobs format text
Setting jobs output format to text
In the following example, we verify more details about the build by querying the output of Virtual User 1, we can see that it monitored all of the Virtual Users to load the data correctly and created the stored procedures and gathered statistics, so we can be sure that the schema build was fully complete.
hammerdb>job 6388A0385EEC03E263531353 1
Virtual User 1: Monitor Thread
Virtual User 1: CREATING TPCC SCHEMA
Virtual User 1: Ssl_cipher {}
Virtual User 1: CREATING DATABASE tpcc
Virtual User 1: CREATING TPCC TABLES
Virtual User 1: Loading Item
Virtual User 1: Loading Items - 50000
Virtual User 1: Loading Items - 100000
Virtual User 1: Item done
Virtual User 1: Monitoring Workers...
Virtual User 1: Workers: 4 Active 0 Done
Virtual User 1: Workers: 0 Active 4 Done
Virtual User 1: CREATING TPCC STORED PROCEDURES
Virtual User 1: GATHERING SCHEMA STATISTICS
Virtual User 1: TPCC SCHEMA COMPLETE
Querying Job Output
As we ran a workload we can now query the configuration of HammerDB when the job was run, in the example we query the database, benchmark, timestamp for the job and the dict at the time it was run.
We can also query the job result, the transaction count and the captured xtprof timings. By default the summary timings are reported, however by adding the vuid you can also drill down into the timings for a specific virtual user.
HammerDB CLI jobs are also compatible with the HammerDB Web Service command allowing the querying of the jobs output over HTTP. It is planned to enhance this webservice to provide an interactive to more easily visualise and analyse job data.
Summary
The HammerDB jobs interface has been added to provide a central repository stored in a SQLite database where all output and configuration related to a workload is stored for ease of querying at a later point. The jobs interface provides a foundation for future development to provide more comprehensive insight into job related data.
From version v4.6 HammerDB allows you to run the Command Line Interface in both interactive and scripted sessions using a Python interpreter as an alternative to the default Tcl environment on both Linux and Windows.
Python Version Dependency
HammerDB will rely on the system installed Python interpreter and at a specific version as described in the following table. On Windows you need to install Python from www.python.org rather than the Windows app store to ensure that the required libraries are installed.
Linux
3.8
Red Hat Enterprise Linux
3.6
Windows
3.10
If you need a different version of Python you can build HammerDB from source as detailed in the documentation to use any version of Python 3 that you wish.
Starting the CLI in Python Mode
To start HammerDB in Python mode run the hammerdbcli tool with “py” or “python” as the first argument. HammerDB will show the prompt “hammerdb>>>” to indicate that it is running a Python interpreter.
C:\Program Files\HammerDB-4.6>hammerdbcli py
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help()" for a list of commands
hammerdb>>>
In this mode HammerDB will now accept commands and scripts in Python format enabling integration with an existing Python environment. A Python script can be run from an external command or script using the auto argument and a .py extension to the script.
print("SETTING CONFIGURATION")
dbset('db','mssqls')
diset('tpcc','mssqls_driver','timed')
diset('tpcc','mssqls_rampup',0)
diset('tpcc','mssqls_duration',1)
vuset('logtotemp',1)
loadscript()
print("SEQUENCE STARTED")
for z in [1,2,4]:
print(z," VU TEST")
vuset('vu',z)
vucreate()
vurun()
vudestroy()
print("TEST SEQUENCE COMPLETE")
Running this script returns output as follows using the Python loop to drive HammerDB.
hammerdb>>>source('cliexample.py')
hammerdb>>>SETTING CONFIGURATION
Database set to MSSQLServer
Value timed for tpcc:mssqls_driver is the same as existing value timed, no change made
Changed tpcc:mssqls_rampup from 2 to 0 for MSSQLServer
Changed tpcc:mssqls_duration from 5 to 1 for MSSQLServer
Script loaded, Type "print script" to view
SEQUENCE STARTED
1 VU TEST
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Logging activated
to C:/Users/Hdb/AppData/Local/Temp/hammerdb.log
2 Virtual Users Created with Monitor VU
Vuser 1:RUNNING
Vuser 1:Initializing xtprof time profiler
Vuser 1:Beginning rampup time of 0 minutes
Vuser 1:Rampup complete, Taking start Transaction Count.
Vuser 1:Timing test period of 1 in minutes
Vuser 2:RUNNING
Vuser 2:Initializing xtprof time profiler
Vuser 2:Processing 10000000 transactions with output suppressed...
Vuser 1:1 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:1 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 39945 NOPM from 92893 SQL Server TPM
Vuser 1:Gathering timing data from Active Virtual Users...
Vuser 2:FINISHED SUCCESS
Vuser 1:Calculating timings...
Vuser 1:Writing timing data to C:/Users/Hdb/AppData/Local/Temp/hdbxtprofile.log
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
vudestroy success
2 VU TEST
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Vuser 3 created - WAIT IDLE
Logging activated
to C:/Users/Hdb/AppData/Local/Temp/hammerdb.log
3 Virtual Users Created with Monitor VU
Vuser 1:RUNNING
Vuser 1:Initializing xtprof time profiler
Vuser 1:Beginning rampup time of 0 minutes
Vuser 1:Rampup complete, Taking start Transaction Count.
Vuser 1:Timing test period of 1 in minutes
Vuser 2:RUNNING
Vuser 2:Initializing xtprof time profiler
Vuser 2:Processing 10000000 transactions with output suppressed...
Vuser 3:RUNNING
Vuser 3:Initializing xtprof time profiler
Vuser 3:Processing 10000000 transactions with output suppressed...
Vuser 1:1 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:2 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 81178 NOPM from 189455 SQL Server TPM
Vuser 1:Gathering timing data from Active Virtual Users...
Vuser 3:FINISHED SUCCESS
Vuser 2:FINISHED SUCCESS
Vuser 1:Calculating timings...
Vuser 1:Writing timing data to C:/Users/Hdb/AppData/Local/Temp/hdbxtprofile.log
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
vudestroy success
4 VU TEST
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Vuser 3 created - WAIT IDLE
Vuser 4 created - WAIT IDLE
Vuser 5 created - WAIT IDLE
Logging activated
to C:/Users/Hdb/AppData/Local/Temp/hammerdb.log
5 Virtual Users Created with Monitor VU
Vuser 1:RUNNING
Vuser 1:Initializing xtprof time profiler
Vuser 1:Beginning rampup time of 0 minutes
Vuser 1:Rampup complete, Taking start Transaction Count.
Vuser 1:Timing test period of 1 in minutes
Vuser 2:RUNNING
Vuser 2:Initializing xtprof time profiler
Vuser 2:Processing 10000000 transactions with output suppressed...
Vuser 3:RUNNING
Vuser 3:Initializing xtprof time profiler
Vuser 3:Processing 10000000 transactions with output suppressed...
Vuser 4:RUNNING
Vuser 4:Initializing xtprof time profiler
Vuser 4:Processing 10000000 transactions with output suppressed...
Vuser 5:RUNNING
Vuser 5:Initializing xtprof time profiler
Vuser 5:Processing 10000000 transactions with output suppressed...
Vuser 1:1 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:4 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 118762 NOPM from 276763 SQL Server TPM
Vuser 1:Gathering timing data from Active Virtual Users...
Vuser 5:FINISHED SUCCESS
Vuser 4:FINISHED SUCCESS
Vuser 3:FINISHED SUCCESS
Vuser 2:FINISHED SUCCESS
Vuser 1:Calculating timings...
Vuser 1:Writing timing data to C:/Users/Hdb/AppData/Local/Temp/hdbxtprofile.log
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
vudestroy success
TEST SEQUENCE COMPLETE
hammerdb>>>
Python Performance and the GIL
You should already be aware that due to the Python GIL impacting multithreading performance it is not possible to drive a high-performance database workload directly from Python.
Therefore, although on both Linux and Windows, you will see Python as the top process in performance monitoring tools when running the workload.
The multithreading capabilities of Tcl are embedded into Python ensuring that the same high levels of performance can be achieved as when running directly in Tcl.
How the Python CLI Interface works
The HammerDB CLI interface uses a package called tclpy to embed HammerDB into the Python interpreter. Therefore, advanced users can also use the command tclpy.eval to call HammerDB commands directly and tclpy.eval(‘vurun’) is functionally equivalent to vurun() but will return output values and therefore in the example below this is how vurun can be called in v4.6 to capture the jobid.
Similarly, as we are running an embedded interpreter any redirection of stdout to capture should be passed to the embedded Tcl level and not at the Python level. See the Python Docker script examples for how this is done.
Calling Python from Tcl
Although the examples in this post show HammerDB being called from a Python interpreter it is also possible to load the same package into HammerDB being run with a Tcl interpreter and call Python functions with the “py eval” command, for example:
HammerDB CLI v4.6
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /tmp/hammer.DB using existing tables (36,864 KB)
hammerdb>package require tclpy
0.4
hammerdb>py eval {divide = lambda x: 1.0/int(x)}
hammerdb>set d [py call divide 16]
0.0625
Summary
From HammerDB v4.6, Python users can run the HammerDB CLI in interactive or scripted mode using a Python interpreter, yet still take advantage of the advanced high performance mulithreading of Tcl. This way HammerDB can extended to take advantage of the features of both languages.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. In contrast, a frequent question when it comes to HammerDB is why is it written in Tcl? Surely any language will do?
This post addresses both questions to illustrate exactly why HammerDB is written in Tcl and why using Python to benchmark a database can result in poor performance and misleading results. To do this, we are going to rewrite HammerDB in Python and run a series of tests on a 2 socket Intel(R) Xeon(R) Platinum 8280L server to see how and why Tcl is 700% faster than Python for database benchmarking*
Background and Concepts
To begin with, you should be familiar with the concepts of parallelism vs concurrency and why it is vital that your benchmark should run in parallel so that you are testing the concurrency of the database. An introduction to these concepts is given in the following post.
So we are not actually going to rewrite HammerDB in Python, however it is trivial to write a command line driver script in Python as all the hard work in creating the schema and writing the stored procedures has already been done. (We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test). So instead we are going to take a cut down version of the HammerDB TPROC-C driver script and do the same in Python and use the HammerDB infrastructure to measure performance. For this example, we are going to use PostgreSQL stored procedures in PostgreSQL 14.1.
So firstly we have the Tcl based driver script called pgtest_thread.tcl
#!/usr/bin/python
import psycopg2
import sys
import random
import math
from datetime import datetime
import threading
def gettimestamp():
tstamp = datetime.now().strftime("%Y%m%d%H%M%S")
return tstamp
def nurand(iConst,x,y,C):
nrnd = ((((random.randint(0,iConst) | random.randint(x,y)) + C) % (y - x + 1 )) + x)
return nrnd
def randname(num):
namearr = [ "BAR", "OUGHT", "ABLE", "PRI", "PRES", "ESE", "ANTI", "CALLY", "ATION", "EING" ]
pt1 = namearr[math.floor((num / 100) % 10)]
pt2 = namearr[math.floor((num / 10) % 10)]
pt3 = namearr[math.floor((num / 1) % 10)]
name = pt1 + pt2 + pt3
return name
def neword(cur, no_w_id, w_id_input):
#print("neword")
no_d_id = random.randint(1,10)
no_c_id = random.randint(1,3000)
ol_cnt = random.randint(5,15)
date = gettimestamp()
cur.execute('call neword(%s,%s,%s,%s,%s,0.0,\'\',\'\',0.0,0.0,0,TO_TIMESTAMP(%s,\'YYYYMMDDHH24MISS\')::timestamp without time zone)',(no_w_id,w_id_input,no_d_id,no_c_id,ol_cnt,date))
rows = cur.fetchall()
#print(rows)
def payment(cur, p_w_id, w_id_input):
#print("payment")
p_d_id = random.randint(1,10)
x = random.randint(1,100)
y = random.randint(1,100)
if (x <= 85):
p_c_d_id = p_d_id
p_c_w_id = p_w_id
else:
p_c_d_id = random.randint(1,10)
p_c_w_id = random.randint(1,w_id_input)
while (p_c_w_id == p_w_id) and (w_id_input != 1):
p_c_w_id = random.randint(1,w_id_input)
nrnd = nurand(255,0,999,123)
name = randname(nrnd)
p_c_id = random.randint(1,3000)
if (y <= 85):
byname = 1
else:
byname = 0
name = ""
p_h_amount = random.randint(1,5000)
h_date = gettimestamp()
p_c_since = gettimestamp()
cur.execute('call payment(%s,%s,%s,%s,%s,%s,\'0\',%s,%s,\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',\'\',TO_TIMESTAMP(%s,\'YYYYMMDDHH24MISS\')::timestamp without time zone,0.0,0.0,0.0,\'\',TO_TIMESTAMP(%s,\'YYYYMMDDHH24MISS\')::timestamp without time zone)',(p_w_id,p_d_id,p_c_w_id,p_c_d_id,byname,p_h_amount,name,p_c_id,p_c_since,h_date))
rows = cur.fetchall()
#print(rows)
def delivery(cur, w_id):
#print("delivery")
carrier_id = random.randint(1,10)
date = gettimestamp()
cur.execute('call delivery(%s,%s,TO_TIMESTAMP(%s,\'YYYYMMDDHH24MISS\')::timestamp without time zone)',(w_id,carrier_id,date))
#rows = cur.fetchall()
#print(rows)
def slev(cur, w_id, stock_level_d_id):
#print("slev" )
threshold = random.randint(10, 20)
cur.execute('call slev(%s,%s,%s,0)',(w_id,stock_level_d_id,threshold))
rows = cur.fetchall()
#print(rows)
def ostat(cur, w_id):
#print("ostat")
d_id = random.randint(1, 10)
nrnd = nurand(255,0,999,123)
name = randname(nrnd)
c_id = random.randint(1, 3000)
y = random.randint(1, 100)
if (y <= 60):
byname = 1
else:
byname = 0
name = ""
date = gettimestamp()
cur.execute('call ostat(%s,%s,%s,%s,%s,\'\',\'\',0.0,0,TO_TIMESTAMP(%s,\'YYYYMMDDHH24MISS\')::timestamp without time zone,0,\'\')',(w_id,d_id,c_id,byname,name,date))
rows = cur.fetchall()
#print(rows)
def runtpcc():
total_iterations = 1000000
conn = psycopg2.connect(host="localhost",port="5432",database="tpcc",user="tpcc",password="tpcc")
conn.set_session(autocommit=True)
cur = conn.cursor()
cur.execute("select max(w_id) from warehouse")
w_id_input = cur.fetchone()[0]
w_id = random.randint(1, w_id_input)
cur.execute("select max(d_id) from district")
d_id_input = cur.fetchone()[0]
stock_level_d_id = random.randint(1, d_id_input)
print ("Processing", total_iterations, "transactions without output suppressed...")
for x in range(total_iterations):
choice = random.randint(1, 23)
if (choice <= 10):
neword (cur, w_id, w_id_input)
elif (choice <= 20):
payment (cur,w_id, w_id_input)
elif (choice <= 21):
delivery (cur, w_id)
elif (choice <= 22):
slev (cur, w_id, stock_level_d_id)
elif (choice <= 23):
ostat (cur, w_id)
if (x == total_iterations):
conn.close()
def main():
threads = []
for n in range(64):
t = threading.Thread(target=runtpcc)
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == '__main__':
main()
It should be clear that these driver scripts do exactly the same thing, they create multiple threads and loop calling the 5 TPROC-C stored procedures meaning that on the PostgreSQL database the workload itself is identical only the language calling the stored procedures is different.
Building the Test Schema and Timing Script
Next we are going to build a PostgreSQL test schema using the HammerDB CLI as follows:
Finally we are going to build a HammerDB timing script. The key thing to note is that we are going to set pg_total_iterations to 1, this means that we have a special form of driver script that will time the transactions on the database but will not run any transactions itself to impact the load. This way we can run our external Tcl and Python test scripts and capture the results.
If all is configured correctly when running either our Tcl or Python driver script we will see output such as follows, note that Vuser 2 shows FINISHED SUCCESS just after it starts so the only activity that this script is doing on the database is capturing the NOPM and TPM over a time period, in this example 2 minutes.
$ ./hammerdbcli auto pgtime.tcl
HammerDB CLI v4.4
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
The xml is well-formed, applying configuration
Database set to PostgreSQL
Benchmark set to TPC-C for PostgreSQL
Changed tpcc:pg_superuser from postgres to steve for PostgreSQL
Value postgres for tpcc:pg_defaultdbase is the same as existing value postgres, no change made
Changed tpcc:pg_storedprocs from false to true for PostgreSQL
Changed tpcc:pg_total_iterations from 10000000 to 1 for PostgreSQL
Clearing Script, reload script to activate new setting
Script cleared
Changed tpcc:pg_driver from test to timed for PostgreSQL
Changed tpcc:pg_rampup from 2 to 0 for PostgreSQL
Changed tpcc:pg_duration from 5 to 2 for PostgreSQL
Script loaded, Type "print script" to view
Transaction Counter Started
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Logging activated
to /tmp/hammerdb.log
2 Virtual Users Created with Monitor VU
Vuser 1:RUNNING
Vuser 1:Beginning rampup time of 0 minutes
Vuser 1:Rampup complete, Taking start Transaction Count.
0 PostgreSQL tpm
Vuser 1:Timing test period of 2 in minutes
Vuser 2:RUNNING
Vuser 2:Processing 1 transactions with output suppressed...
Vuser 2:FINISHED SUCCESS
3650220 PostgreSQL tpm
4245132 PostgreSQL tpm
4203948 PostgreSQL tpm
4211748 PostgreSQL tpm
4203648 PostgreSQL tpm
Timer: 1 minutes elapsed
Vuser 1:1 ...,
4367244 PostgreSQL tpm
4265898 PostgreSQL tpm
4320510 PostgreSQL tpm
4258518 PostgreSQL tpm
4426578 PostgreSQL tpm
4413780 PostgreSQL tpm
Timer: 2 minutes elapsed
Vuser 1:2 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:1 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 1844256 NOPM from 4232155 PostgreSQL TPM
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
Running a single process pre-test
Before we test the multithreading capabilities it is important to callibrate how our respective scripts. For this we will use a slightly modified version for both that removes the threading. We start these running as follows for Python
python3 pgtest_proc.py
and as follows from the HammerDB directory (export the HammerDB ./lib directory into the LD_LIBRARY_PATH first)
./bin/tclsh8.6 pgtest_proc.tcl
Once the workload is started we then run the timing script in another command window and once we get the result we Ctrl-C the driver script to stop the test.
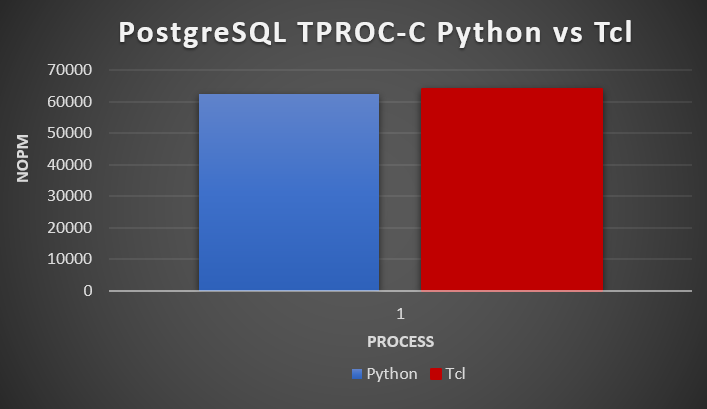
In our single process test we see 62257 NOPM for Python and 64142 NOPM for Tcl giving confidence that the test scripts and methodology are correct (remember that the workload is running in PostgreSQL stored procedures and the test is calling those stored procedures, so we expect the single process result to be very close).
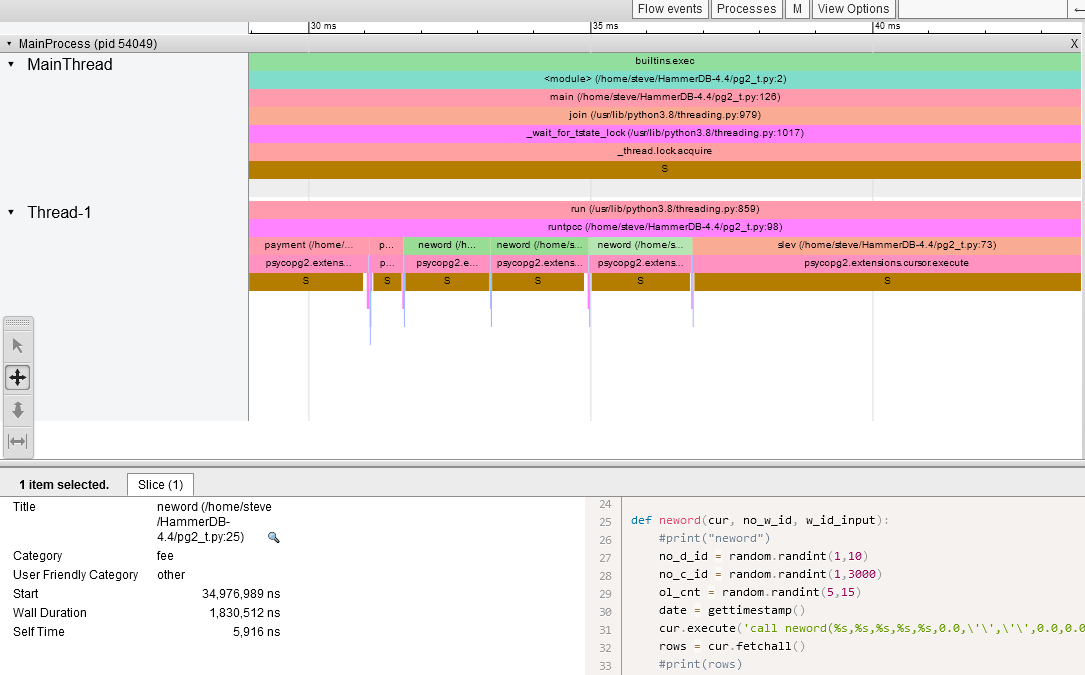
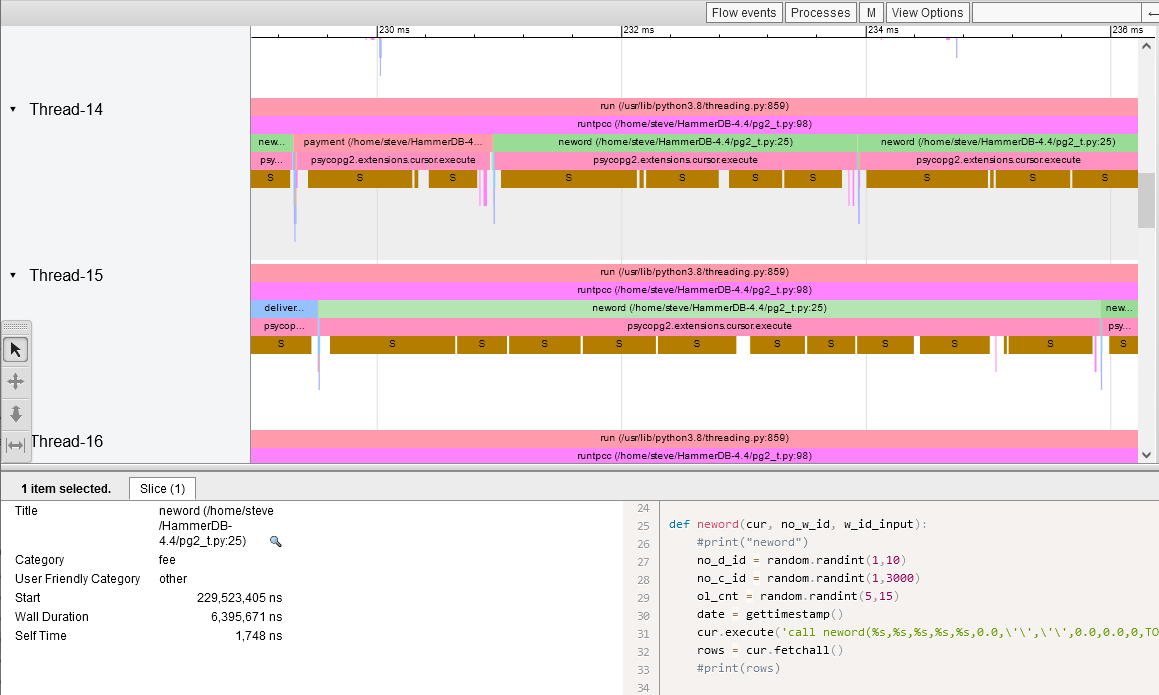
We can also use VizTracer to run the same workload under Python this time in a single thread to understand a little about what the workload should look like. For each stored procedure we calculate the parameters with a number of random operations and then call psycopg2.extensions.cursor.execute, during this we sleep while we wait for the PostgreSQL database to execute the stored procedure and then we run psycopg2.extensions.cursor.fetchall to fetch the results. In total the Wall duration to run the neword stored procedure was 1.8ms.
Running the Mulithreaded Test
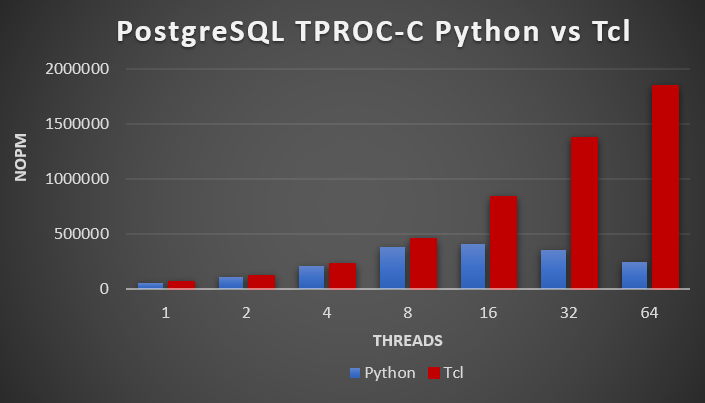
Now lets run a the multithreaded tests shown above. For each test we are going to edit the script to change the number of threads testing at 1,2,4,8,16,32 and 64 threads with the following results.
At 1, 2 or 4 threads we barely notice a difference, however at 64 threads Python gives us 247976 NOPM and Tcl 1844256 NOPM meaning Tcl is more than 700% faster for an identical workload once we start running multiple threads.
So why is there such a marked contrast between an identical workload in Python and Tcl? As an early indication we can take a look at the output from top when running 64 threads. Firstly with Python observe that we have 9 running tasks, 5.8% user CPU utilisation and all of the top postgres processes show as idle.
in contrast the same workload in Tcl shows that we have 64 running tasks (for 64 threads) 53.1% CPU and the postgres processes are all busy running stored procedures.
So, if you have read this far you won’t be surprised that we suspect that the roadblock we have encountered with Python is a major one called the Global Interpreter Lock or GIL that means only one thread can run at any one time. But lets confirm this using the GIL load tool to time the amount of time that the GIL is held for our 64 thread workload. The tool is installed and run as follows:
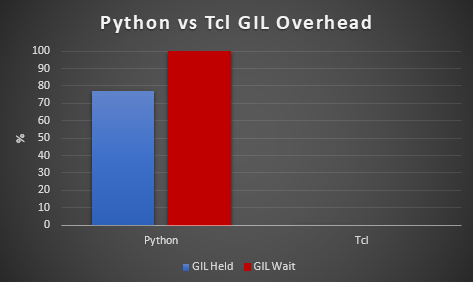
and we add gil_load.start and gil_load.stop to the Python script and run a smaller number of transactions without timing the test. The following is the result. The GIL is held for 77% of the time and the threads wait for the GIL 99.9% of the time. For Tcl this is 0% and 0% respectively because there is no GIL meaning Tcl threads execute in parallel and the workload continues to scale.
The difference between the two also shows that there is time when we are synchronizing between the threads and not running any workload at all. As our results show the more threads we add the worse the performance gets due to this GIL synchronization.
If we now return to VizTracer and perf using the method described here to trace Python with 16 threads we can now see that the Wall Duration time for the neword stored procedure has increased by 300% and we are spending a lot longer sleeping with only one thread allowed to execute at any one time. PostgreSQL can sustain higher throughput but our Python client cannot.
Python GIL PostgreSQL wait events
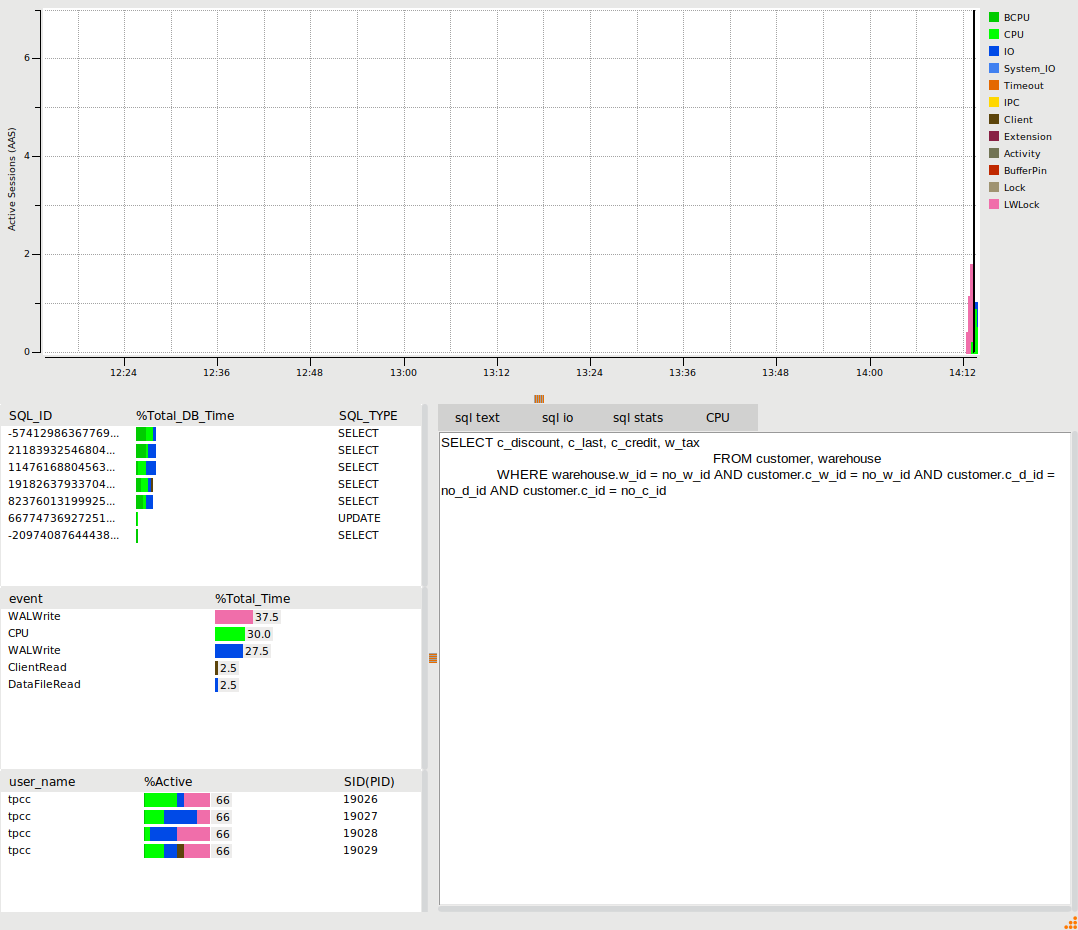
So if the bottleneck is in the client what wait event would we expect to see on our PostgreSQL database? To do this we can use the pg_stat_statements and pg_sentinel packages to query the active session history with the SQL as follows:
with ash as (
select *,ceil(extract(epoch from max(ash_time)over()-min(ash_time)over()))::numeric samples
from pg_active_session_history where ash_time>=current_timestamp - interval '10 minutes'
) select round(100 * count(*)/sum(count(*)) over(),0) as "%", round(count(*)/samples,2) as "AAS",
datname,wait_event_type,wait_event
from ash
group by samples,
datname,wait_event_type,wait_event
order by 1 desc
;
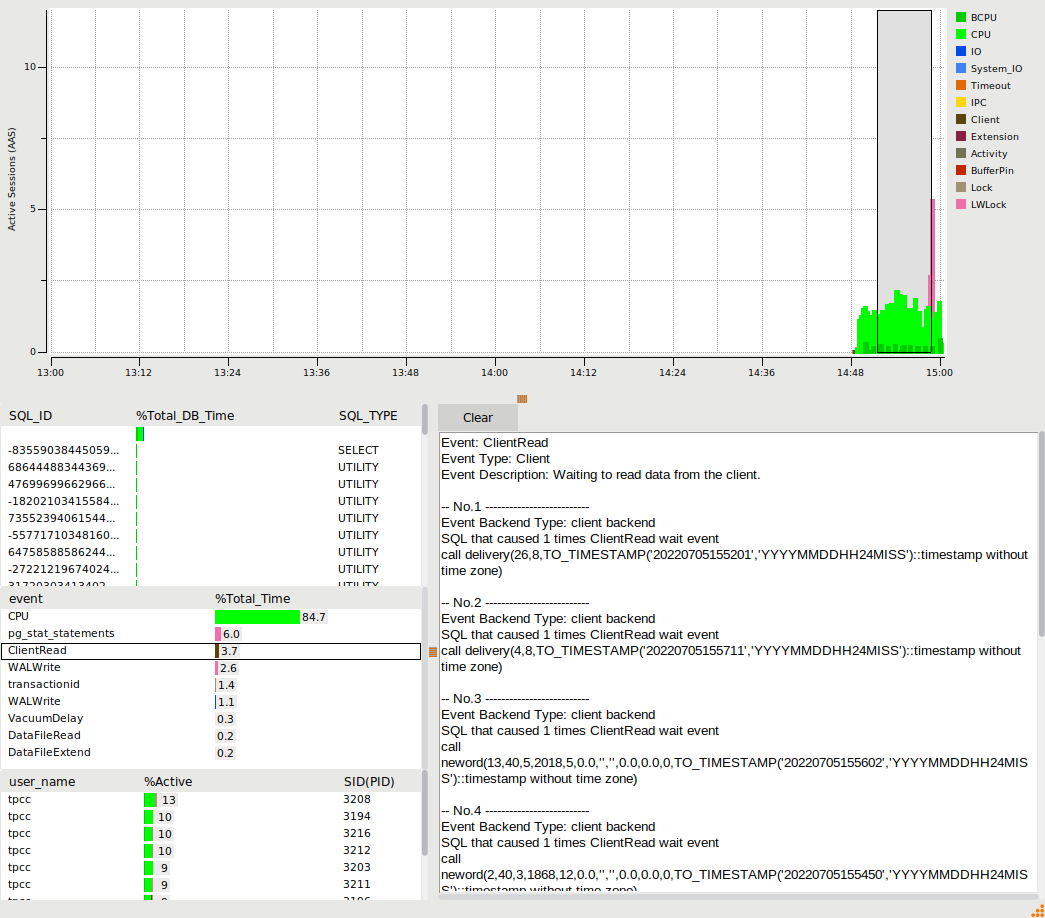
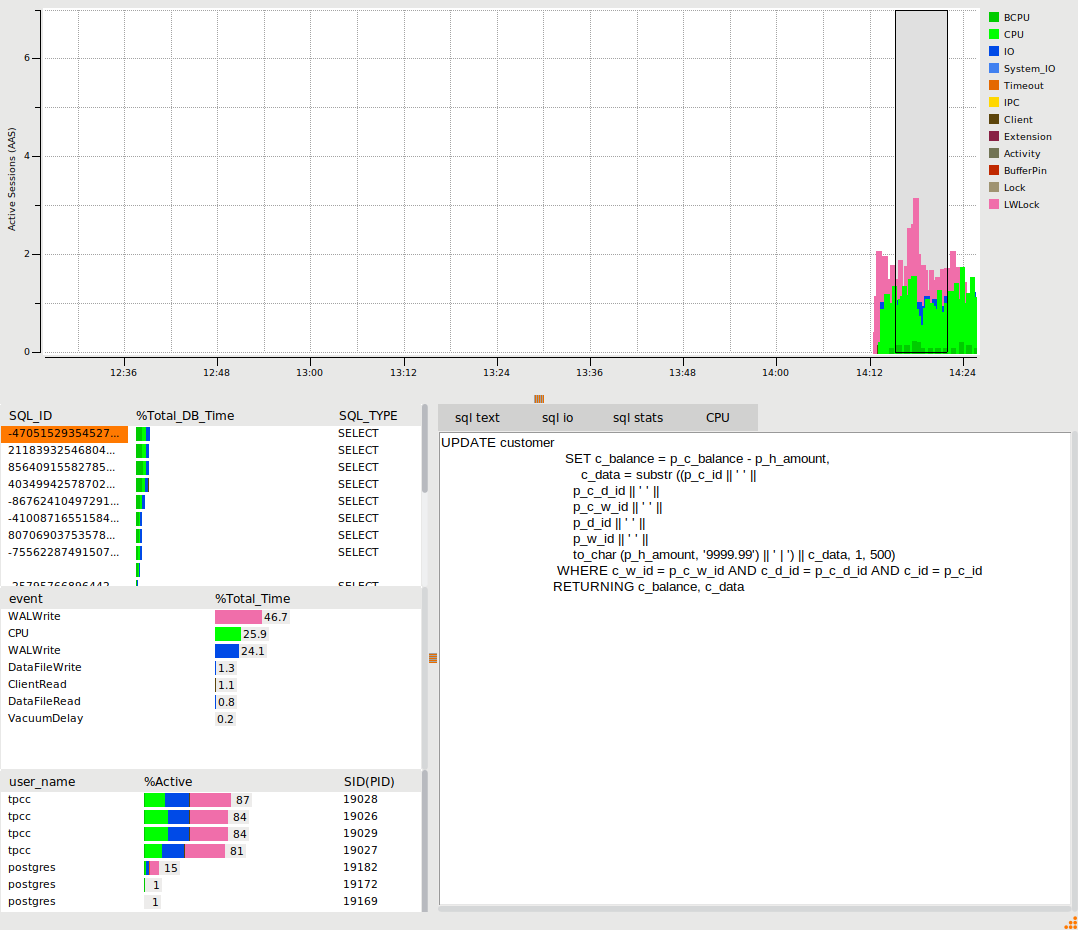
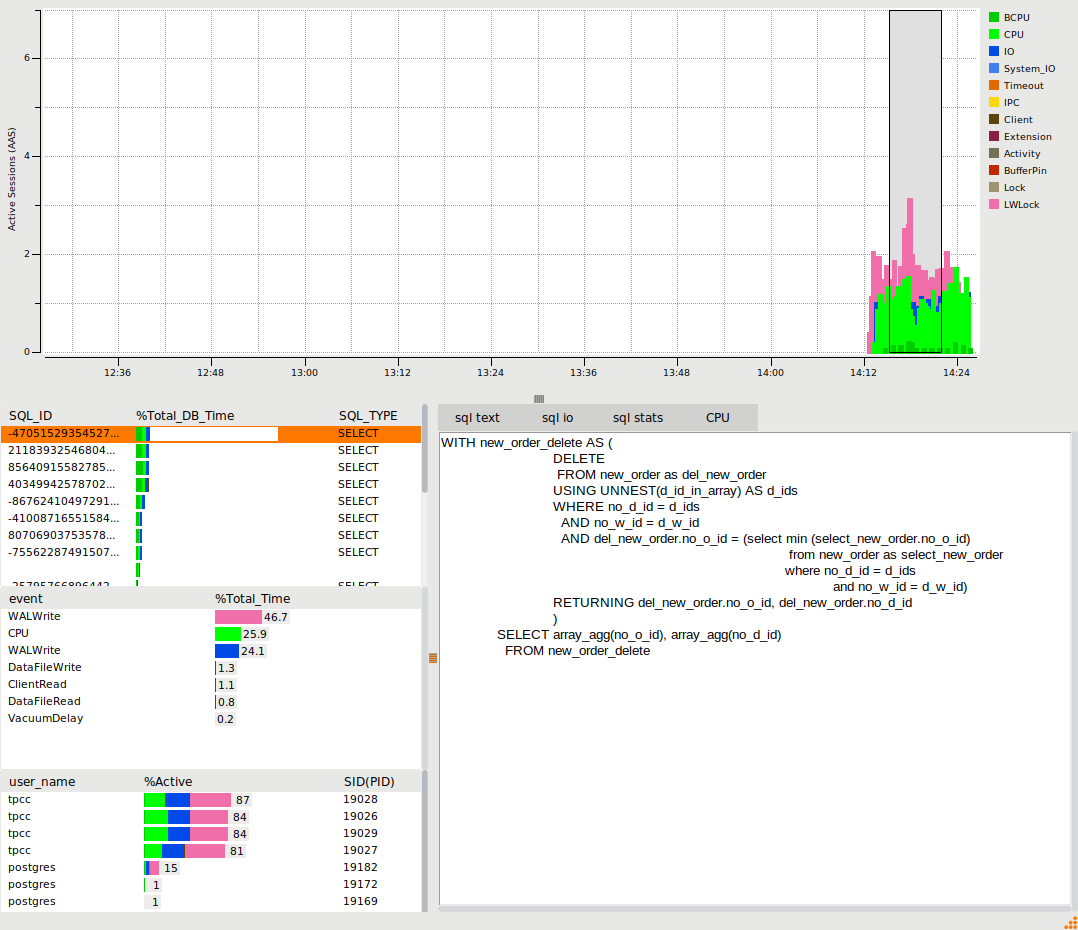
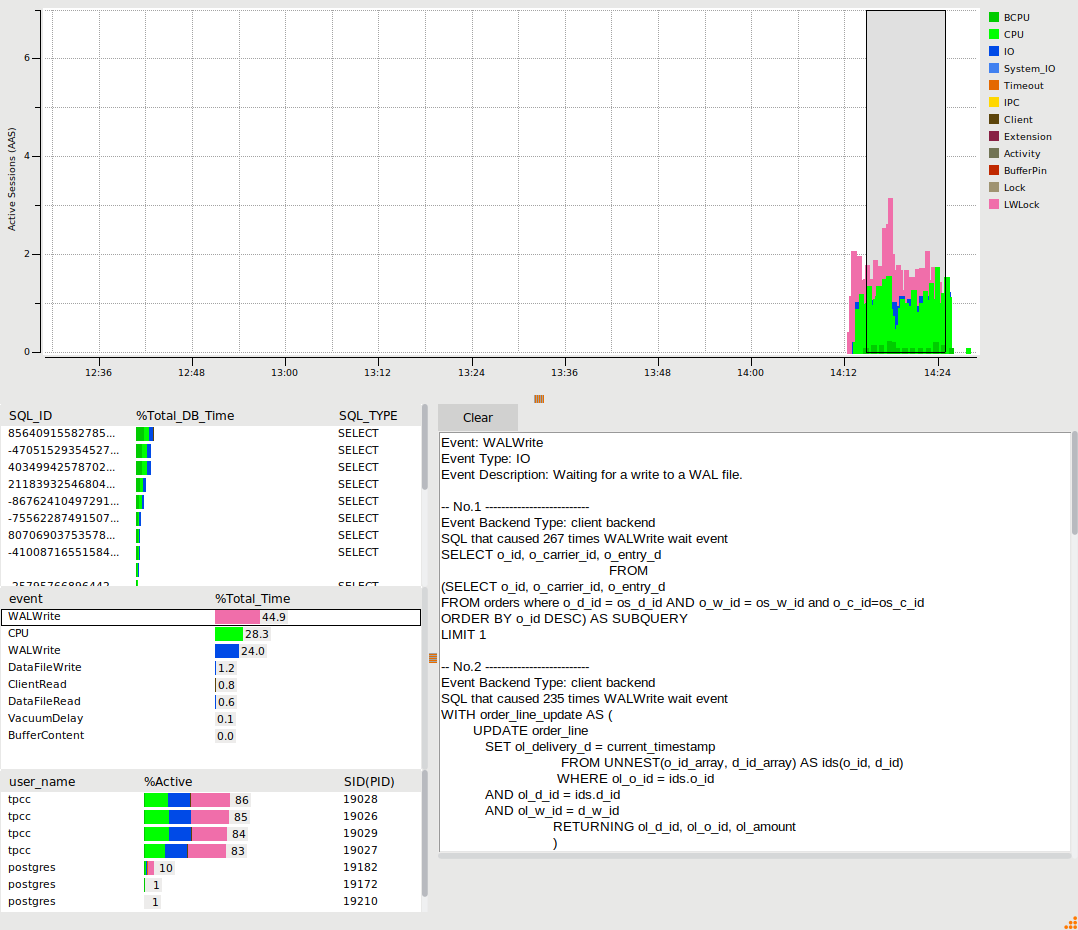
So when using Python we are spending 62% of our time on a Client wait event called ClientRead or in other words PostgreSQL is telling us it is spending most of its time waiting for the Python client to respond, either the transaction has finished and it is waiting for Python to fetch the results or it has already fetched the results and is waiting for the next query to be sent. Either way high waits on ClientRead means we are waiting for the client and not the database. Also note that with the Tcl workload we now start to see some of the LWLock wait events that a database engineer working on scalability would focus on and we can use the HammerDB PostgreSQL statistics viewer to drill down on some of these wait events.
Summary
What we have observed is that the Python GIL makes it impossible to run anything but a single threaded benchmark against a database because the GIL means that only one thread can ever run at one time. For decades databases have been designed to scale to process millions of transactions a minute whilst maintaining database consistency, a serialized benchmark client compromises the ability to compare databases.
HammerDB and its predecessor Hammerora were written in the Tcl language because they were written by database engineers looking to write scalable database benchmarks rather than by application engineers looking to use a particular language. At the time Tcl was the only multi-threaded GIL free scripting language for database access and this still holds true today. (And although the Python test script could run in multiple processes HammerDB is an application simulating multiple virtual users in a GUI and CLI environment requiring the close interaction and control of using multiple threads).
*700% Faster
Although we have seen that Tcl is 700% faster than Python for our example PostgreSQL benchmark we observed that even with Tcl we were only at approximately 50% CPU Utilization. With commerical databases HammerDB can scale to full CPU utilization and 2-3X the transaction rate seen here meaning that in reality the gap between Tcl and Python running against a commericial database is more than 700%.
This post is targeted towards the questions most often asked by non-technical management who want to get up to speed on what HammerDB is (what it isn’t) and how it can benefit their organization.
What is HammerDB?
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software.
HammerDB has graphical and command line interfaces for the Windows and Linux operating systems.
Why HammerDB was developed
Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here. The TPC designed benchmarks for transaction processing (OLTP) and analytics (OLAP) and anyone can run these benchmarks, have them audited by the TPC and published on the official benchmark rankings.
However, although these results are the gold standard of database benchmarking to do so, requires time, expertise and not insignificant cost. Additionally, many databases contain a license clause colloquially known as a De-Witt clause that prevents the publication of non-approved benchmarks.
These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available.
As the TPC makes its specifications available for free, the need was seen for an open source benchmarking application that could leverage the standards written by the TPC yet implemented quickly, easily and at low cost by anyone. Also, when testing a database with a De-Witt clause, it was then possible to produce your own results without having to rely on a particular vendor to publish results of interest.
The HammerDB name
Originally, HammerDB was named Hammerora because the first database the application supported was Oracle. Ora was a common prefix/suffix for Oracle related software, and the name inspired by a genre of classic films and the characters portrayed, in particular for testing Oracle RAC. As more databases were added, the original name was less appropriate and the name HammerDB was suggested and adopted.
HammerDB development
HammerDB was originally developed by Steve Shaw as an employer approved own-time, own-materials project to implement workloads derived from TPC specifications in a user accessible way. An important concept was to simulate database users called Virtual Users in parallel (rather than concurrently) to accurately simulate a real database workload with multiple users running from separate systems. Programming languages such as Java, Lua and Python were unable to support this unique requirement (an application to simulate separate users in multiple threads that do not block or pause each other’s workloads, the Python GIL for example only permits one user to run at any one time) and the design decisions made are discussed in the following post.
Given the increasing importance of open source and the widespread use of HammerDB, the TPC adopted HammerDB in 2019 and now hosts the project on GitHub. Today, the TPC-OSS subcommittee oversees development and approves all modifications made through pull requests.
Usage and industry adoption
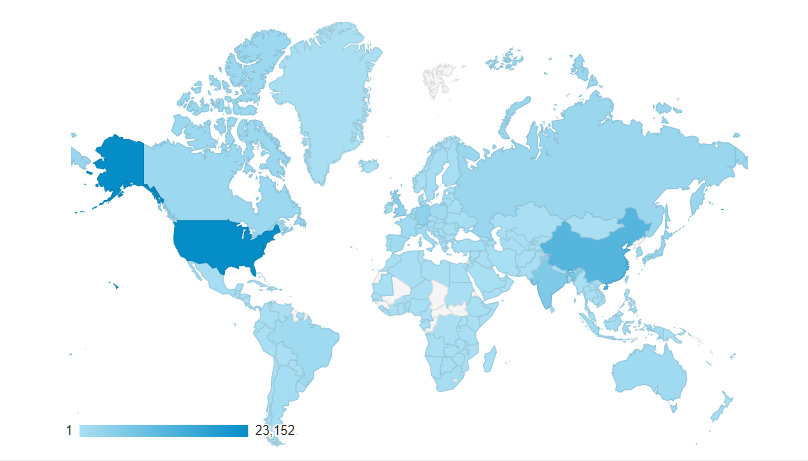
HammerDB maintains a web page under the stats link where the number of downloads can be tracked. HammerDB is used globally, with the areas of use shown in blue on the map below with a darker color showing higher levels of use, with the most popular destinations being the USA and China.
The results of HammerDB workloads have been published by all leading cloud vendors, database software vendors and systems suppliers, HammerDB maintains a collated list of these publications but does not vet or audit results before inclusion.
HammerDB Licensing
HammerDB is open source software licensed under the The GNU General Public License v3.0 (GPLv3) and a quick guide to GPLv3 can be viewed here. HammerDB has dependencies on external open source software and can be built from source.
HammerDB is Free software and consequently engineers should consider not only how they can benefit from using the software but also how they can contribute to the community with code and documentation.
Businesses that depend on open source should consider sponsorship of open source projects or financial support to ensure that the open source they depend on remains freely available.
Supported Databases
HammerDB supports the most popular databases on the db-engines ranking, namely Oracle Database, Microsoft SQL Server, IBM Db2, TimesTen, MySQL, MariaDB, PostgreSQL, Greenplum, Postgres Plus Advanced Server, Citus Data, Amazon Aurora and Amazon Redshift. HammerDB supports these databases running in the cloud and in the enterprise, and will also run workloads against databases derived from the most popular open source databases MySQL and PostgreSQL.
The wide range of database support gives HammerDB an advantage over other database benchmarking tools that only implement workloads against one or two databases, limiting comparison between database engines and assessing relative performance.
Derived Workloads
When testing database performance there are 2 distinct workloads, transactional or OLTP and analytic (data warehouse, decision support) or OLAP. HammerDB supports 2 workloads derived from TPC specifications to test these different requirements, namely TPROC-C derived from TPC-C for OLTP and TPROC-H derived from TPC-H for OLAP.
It is important to note that TPC-C and TPC-H are registered trademarks of the TPC and using the names TPC-C or TPC-H and/or as official metrics such as tpmC or QphH in a non-audited publication is considered a trademark violation and should not be used.
An additional specification called TPC-CH for hybrid transactional/analytical processing (HTAP) is under research and development for inclusion in a future release as TPROC-CH.
In addition to the TPC-C specification for OLTP workloads, the TPC has also developed the TPC-E specification. HammerDB will consider developing a TPC-E derived workload when official benchmark publications are made from at least 3 of the supported databases to ensure a fair representation in an open source version.
The NOPM Metric
When reporting TPROC-C workloads the key metric is known as NOPM or New Orders per Minute. This metric measures the same value as the tpmC metric in an official TPC-C publication, however as noted previously the use of official terminology in derived workloads is not permitted and therefore HammerDB uses NOPM as a derived metric. HammerDB also reports TPM as an engineering metric, it is not a requirement for there to be a fixed relationship between NOPM and TPM across databases and therefore NOPM can be used for comparison of performance between databases whereas TPM is for analysing a particular database engine.
Cached vs Scaled Workloads
The official TPC-C OLTP workload is a what is known as a scaled workload, however a key difference in the HammerDB design was by default to implement a smaller more efficient cached workload based on the same specification that could still give an indication of comparative performance in the same way that the scaled workload could.
A key difference between cached and scaled workloads is the implementation of keying and thinking time to introduce a pause of time between transactions. In a scaled derived TPC-C workload allowing for this keying and thinking time, one Virtual User will complete approximately 1 New Order per Minute and therefore for example 10,000 database sessions will run at approximately 10,000 NOPM and 100,000 sessions at 100,000 NOPM. The workload also outputted the data from the Virtual Users by simulating individual terminals.
Note that HammerDB can also implement a scaled workload with a feature called event-driven scaling. However, this requires a large data set and middleware to manage the large database session count. Instead, most users prefer to implement a cached workload.
When HammerDB was designed, it was clear that where the database software was scalable (initially such as Oracle), CPU performance at full utilization was the key determining factor for database performance. Therefore, a perfectly scaled implementation provided the levels of memory and I/O or disk capacity to reach full CPU utilization.
However, prior to the advent of high performance Solid State Disks (SSDs) to implement such a configuration required a high capacity of hard disk drives (HDDs) in one or many fibre attached storage arrays at considerable expense.
Instead, HammerDB implemented a cached workload by eliminating the keying and thinking time and the requirement for terminals. Now individual Virtual Users don’t pause between transactions and can run at tens of thousands NOPM each. With the reduced I/O footprint, the data each Virtual User requires is much reduced, meaning that most of the workload is cached in memory. This means we can reach full CPU utilization (with scalable database software) quicker and without requiring middleware.
This approach gives us an indication of what an optimally configured scaled configuration with a high I/O and memory capacity can achieve, however be aware that for a production environment you will have measured the CPU’s database potential, but you will need sufficient memory, I/O and scalable database software to make full use of this CPU potential.
Summary
1. HammerDB is a software application for database benchmarking.
2. HammerDB was developed to allow anyone to run database benchmarks quickly, easily and at low cost.
3. HammerDB was designed to scale and is developed in a language that is not restrictied by a Global Interpreter Lock (GIL) that restricts workloads to being single-threaded and instead runs in parallel.
8. HammerDB supports the most popular relational databases on the db-engines ranking.
9. HammerDB runs workloads called TPROC-C and TPROC-H derived from the TPC specifications TPC-C and TPC-H respectively with the NOPM metric, the key metric for measuring transactional performance. Using TPC terminology for non-audited benchmarks violate TPC trademarks.
10. By default HammerDB implements a cached vs a scaled workload but can implement both types of benchmark.
Before building from source, the first question should be, do you need to? HammerDB already provides pre-compiled packages from the download page so if you want to run HammerDB without building it then these packages are all you need.
WHY build from source?
If you are not already familiar with the programming languages that HammerDB uses, then this earlier post serves as an ideal introduction to what makes up the highest performing GIL free database benchmarking application.
You may want to become familiar with all the underlying source code in C or wish to build a distribution where you can verify every single line of source code that goes into HammerDB. All of the source code and dependencies in HammerDB are open source right down to the layer above any 3rd party commercial database drivers for Oracle, SQL Server and Db2. Building from source also enables you to build a distribution right up to date with any of the latest pull requests not yet included in the most recent HammerDB release.
BAWT by Paul Obermeier
HammerDB build automation uses an adapted version of the BAWT package by Paul Obermeier . BAWT is copyrighted by Paul Obermeier and distributed under the 3-clause BSD license.
GETTING STARTED ON LINUX
If you have read what programming languages HammerDB uses, then you will not be too surprised that you will firstly need to install a development environment using the gcc compiler for Linux. You will also need the p7zip tool as well as the Xft font library development packages. The build has been tested on x64 Red Hat 8.X and Ubuntu 20.04.X Linux, with the following example from Red Hat Linux.
The HammerDB Oracle and ODBC for SQL Server client libraries will build without the respective Oracle and SQL Server client libraries, but will need them at runtime. However, the client or server must be installed for all of Db2, MariaDB, PostgreSQL and MySQL for the HammerDB build to be successful. The database installation must include both the include and lib directories.
For Db2 either the server or client can be installed, for example v11.5.7_linuxx64_server_dec.tar.gz.
HammerDB build automation will look for the Db2 installation in the location of the environment variable IBM_DB_DIR set using db2profile tool. Verify that this has been set as follows:
$ echo $IBM_DB_DIR
/home/ibm/sqllib
On Linux MariaDB, PostgreSQL and MySQL include a config command in the bin directory that returns details of the configuration. HammerDB uses these commands to find the headers and libraries needed for the build.
Before running the build, environment variables MARIADB_CONFIG, PG_CONFIG and MYSQL_CONFIG must be set to the location of the respective config commands for each database in the terminal running the build.
On Windows, download and install Visual Studio 2022 , Visual Studio is free for open source developers. An additional gcc compiler will be downloaded and installed locally during the build. The build has been tested on x64 Windows 10 and 11.
As with Linux it is also mandatory to install a database server or client including the development environment of headers and libraries for MariaDB, Db2, MySQL and PostgreSQL.
For Db2 on Windows, there is no db2profile that sets the environment therefore the IBM_DB_DIR environment variable must be set to the location of the Db2 install. Similarly, the MariaDB and MySQL config commands are not available on Windows either and should also be set to the database or client installation directory rather than the bin directory. PostgreSQL for Windows does include the config command and therefore the environment configuration is the same as Linux.
set MARIADB_CONFIG=C:\Program Files\MariaDB\MariaDB Connector C 64-bit
set MYSQL_CONFIG=C:\Program Files\MySQL\MySQL Server 8.0
set PG_CONFIG=C:\Program Files\PostgreSQL\pgsql\bin
set IBM_DB_DIR=C:\Program Files\IBM\SQLLIB
For all database installations on Windows whether client or server verify that the installation has the include, bin and lib directories. On Windows in particular, some installations may not include all the required files for development.
Download HAMMERDB SOURCE
At this stage you will have installed the compiler you need and database client/server installations for MariaDB, Db2, MySQL and PostgreSQL. To reiterate, HammerDB will not build correctly unless you have installed ALL the required database environments.
Next download HammerDB from gitHub by either cloning or downloading. From the main HammerDB GitHub page use the clone URL or the Download Zip link from the master branch.
If cloning you will have a directory called “HammerDB” or extracting the zipfile a directory called “HammerDB-master”.
RUNNING THE BUILD
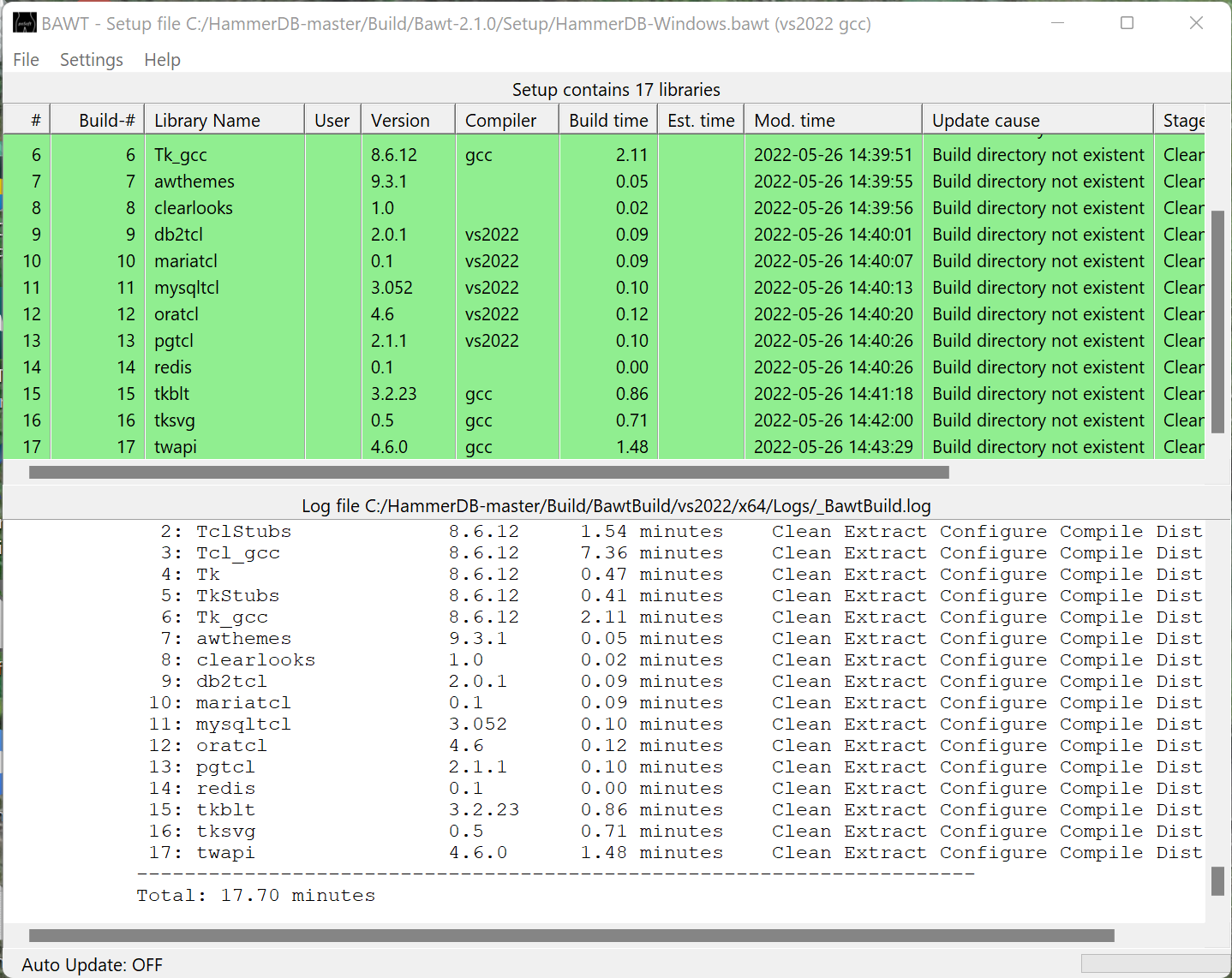
Navigate to the Build\Bawt-2.1.0 directory with the command line for both Linux and Windows. Note that during the build an InputLibs directory will be created and all HammerDB libraries downloaded and under the Build directory a BawtBuild directory will be created where the installation will take place. Therefore, sufficient disk space and permissions must be available for the build to take place.
Within the command line you are running the build make sure that you have correctly set all the MARIADB_CONFIG, MYSQL_CONFIG, PG_CONFIG, and IBM_DB_DIR environment variables used during the build and run the Build-Linux.sh command for Linux ./Build-Linux.sh x64 Setup/HammerDB-Linux.bawt update and Build-Windows.bat commands for Windows ./Build-Windows.bat x64 vs2022+gcc Setup/HammerDB-Windows.bawt update, the command sequence will look similar to the following on Linux:
set MARIADB_CONFIG=C:\Program Files\MariaDB\MariaDB Connector C 64-bit
set MYSQL_CONFIG=C:\Program Files\MySQL\MySQL Server 8.0
set PG_CONFIG=C:\Program Files\PostgreSQL\pgsql\bin
set IBM_DB_DIR=C:\Program Files\IBM\SQLLIB
Build-Windows.bat x64 vs2022+gcc Setup\HammerDB-Windows.bawt update
The first step the build will take is to download the required packages and build instructions from www.hammerdb.com, On Windows the MYSYS/MinGW package will also be downloaded. These will be stored in the Bawt-2.1.0/InputLibs directory. Both checksums and modification times are verified with the remote packages. If a package is already present with the same checksum and modification time, it will not be downloaded again if already present. Also some packages such as Tcl have been modified from the original and therefore only the packages from www.hammerdb.com should be used.
You now have your own distribution of HammerDB with the latest source code. You can run the hammerdbcli librarycheck command to verify that the libraries built correctly.
/opt/HammerDB/Build/BawtBuild/Linux/x64/Release/Distribution$ ls
HammerDB-4.4 HammerDB-4.4-Linux.tar.gz
$ cd HammerDB-4.4
/opt/HammerDB/Build/BawtBuild/Linux/x64/Release/Distribution/HammerDB-4.4$ ./hammerdbcli
HammerDB CLI v4.4
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
hammerdb>librarycheck
Checking database library for Oracle
Success ... loaded library Oratcl for Oracle
Checking database library for MSSQLServer
Success ... loaded library tdbc::odbc for MSSQLServer
Checking database library for Db2
Success ... loaded library db2tcl for Db2
Checking database library for MySQL
Success ... loaded library mysqltcl for MySQL
Checking database library for PostgreSQL
Success ... loaded library Pgtcl for PostgreSQL
Checking database library for MariaDB
Success ... loaded library mariatcl for MariaDB
You can also browse all of the C source code for the libraries you have built in the Build directory.
Having built the distribution yourself it should be clear that as the database libraries are dynamically linked when you install the distribution on another system you will also need to install the database clients on that system.
For example on Linux we have a check that fails because the MariaDB libraries cannot be found and we can verify this with the ldd command.
hammerdb>librarycheck
...
Checking database library for MariaDB
Error: failed to load mariatcl - couldn't load file "/opt/HammerDB/Build/BawtBuild/Linux/x64/Release/Distribution/HammerDB-4.4/lib/mariatcl0.1/libmariatcl0.1.so": libmariadb.so.3: cannot open shared object file: No such file or directory
Ensure that MariaDB client libraries are installed and the location in the LD_LIBRARY_PATH environment variable
$ ldd libmariatcl0.1.so
linux-vdso.so.1 (0x00007ffd534db000)
libmariadb.so.3 => not found
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f259d2f9000)
/lib64/ld-linux-x86-64.so.2 (0x00007f259d513000)
When we install this dependent library and tell HammerDB where to find it:
For an example Windows this time we cannot load the MySQL library.
HammerDB CLI v4.4
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
hammerdb>librarycheck
...
Checking database library for MySQL
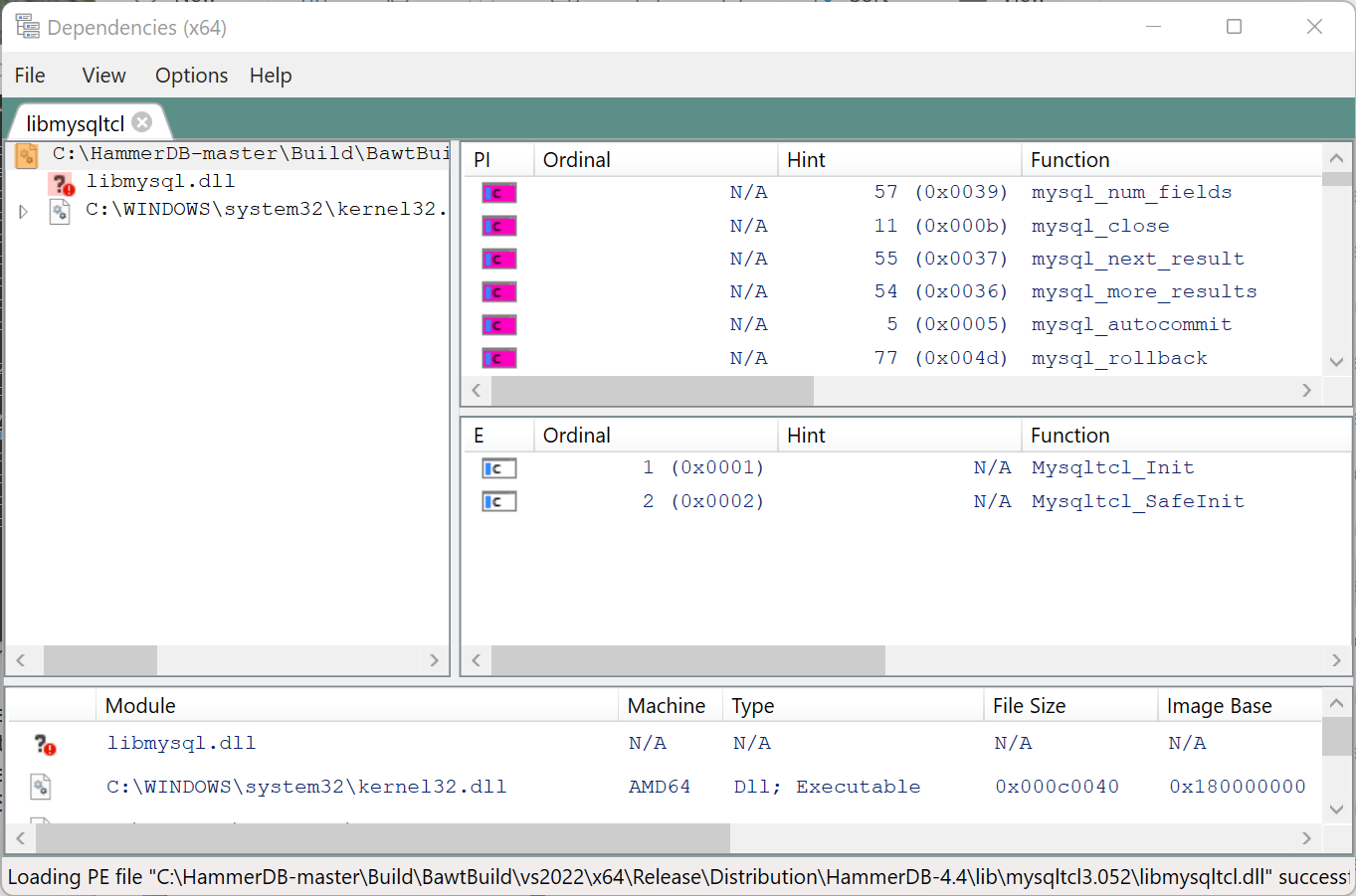
Error: failed to load mysqltcl - couldn't load library "C:/HammerDB-master/Build/BawtBuild/vs2022/x64/Release/Distribution/HammerDB-4.4/lib/mysqltcl3.052/libmysqltcl.dll": No error
Ensure that MySQL client libraries are installed and the location in the PATH environment variable
hammerdb>
We run the DependenciesGui from the dependencies tool, load libmysqltcl.dll and it shows we cannot find libmysql.dll.
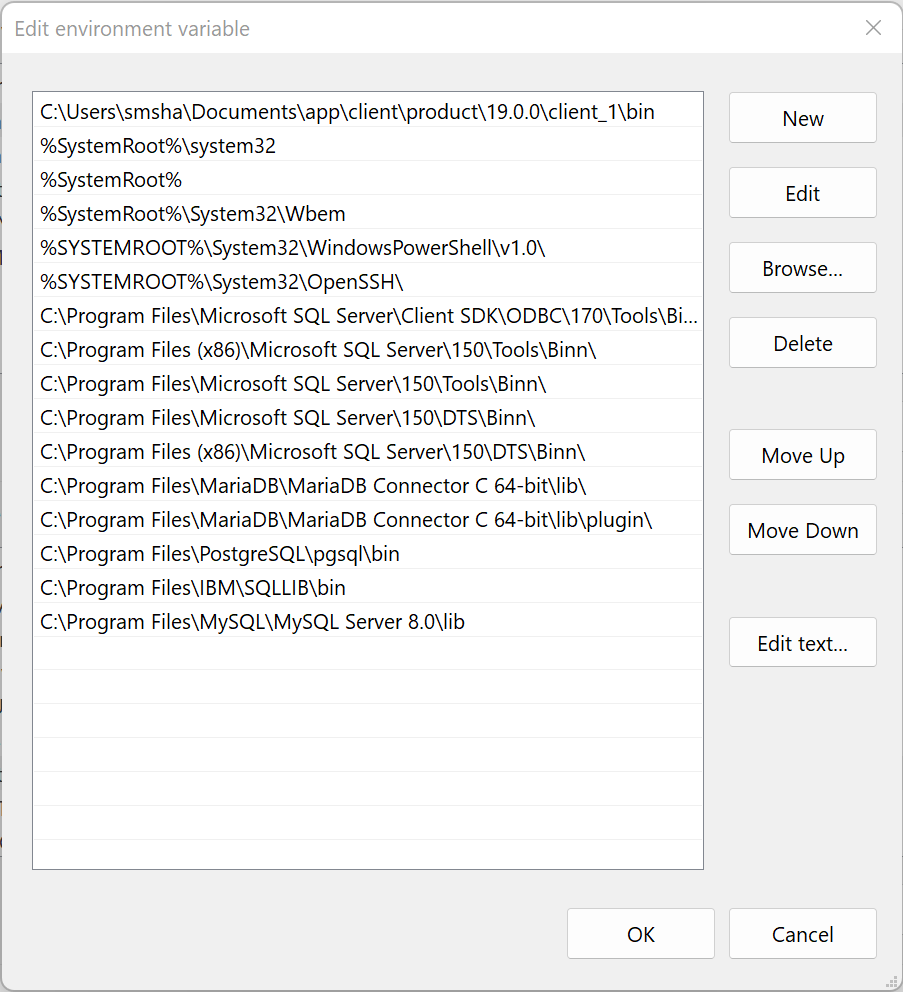
After installing MySQL we set the environment variable to find the library.
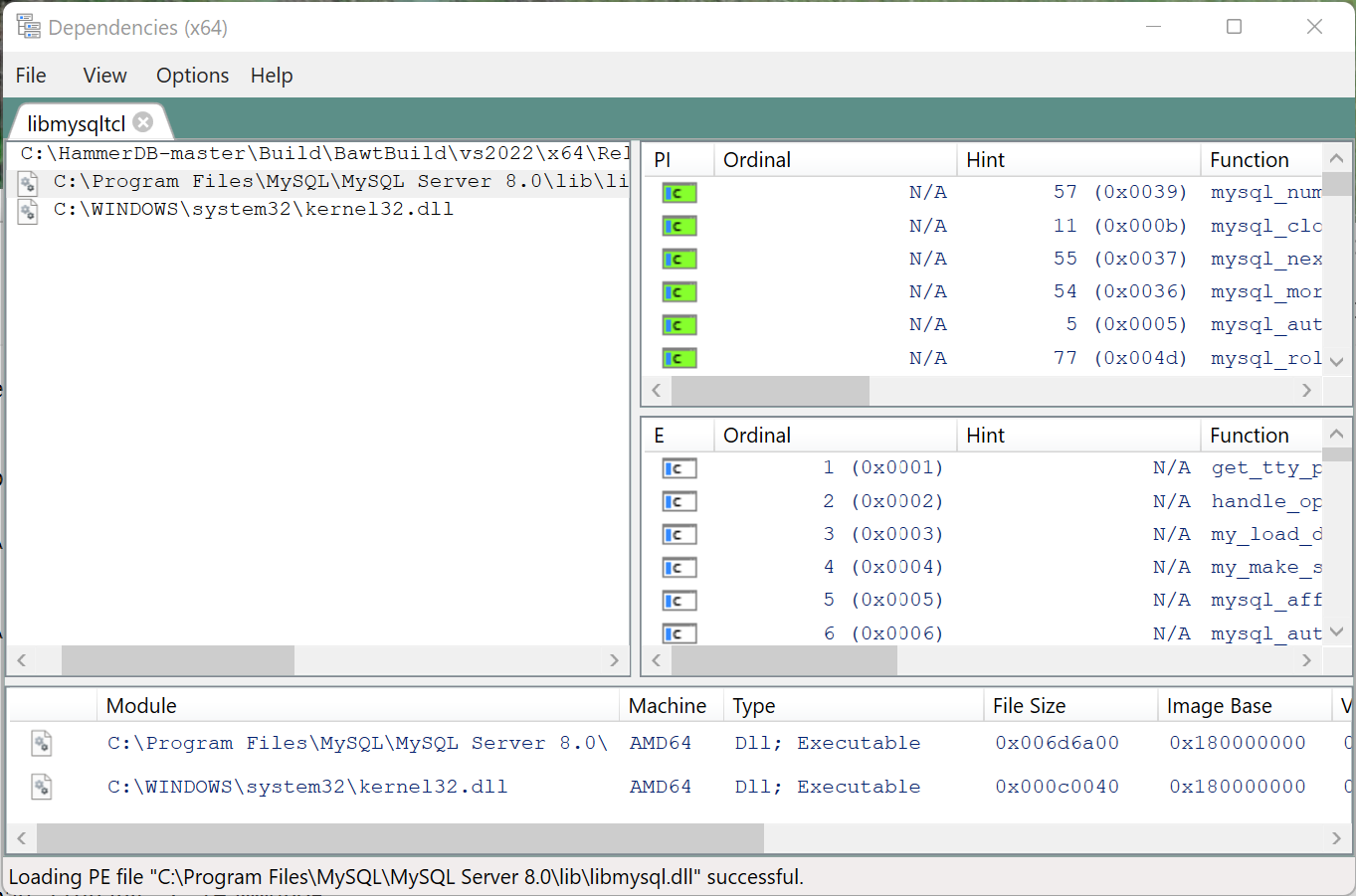
and verify with the Dependencies GUI that now all dependencies can be found.
We can now confirm that the MySQL package can be correctly loaded.
HammerDB CLI v4.4
Copyright (C) 2003-2022 Steve Shaw
Type "help" for a list of commands
hammerdb>librarycheck
Checking database library for Oracle
Success ... loaded library Oratcl for Oracle
Checking database library for MSSQLServer
Success ... loaded library tdbc::odbc for MSSQLServer
Checking database library for Db2
Success ... loaded library db2tcl for Db2
Checking database library for MySQL
Success ... loaded library mysqltcl for MySQL
Checking database library for PostgreSQL
Success ... loaded library Pgtcl for PostgreSQL
Checking database library for MariaDB
Success ... loaded library mariatcl for MariaDB
hammerdb>
SUMMARY
You have now learnt how to build your own HammerDB from source. This gives you access to all of the source code and see how HammerDB is built for a released distribution to enable you to build your own.
The most popular interface to HammerDB is using the GUI, however demand for running HammerDB workloads in environments without GUI interfaces led to the development of the CLI. From v3.2 cloud based usage led to the development of a HammerDB HTTP based web service interface with output data stored in a SQLite database repository. From v4.3 this web interface has been enhanced to add command line functionality to the service as well as extending the ability to query the database of configuration, results and timing data to be returned in JSON format, enabling a long-term repository of HammerDB benchmark data for integrating HammerDB into service based cloud environments.
Configuring and starting the Webservice
The webservice configuration is set in the generic.xml file in the config directory. ws_port defines on which port to start the HTTP service, whilst sqlite_db sets the location of the SQLite repository database. The default value of TMP allows HammerDB to find a suitable temp directory in which to store the database. if :memory: is given an in-memory database will be used, however some functionality such as the storing of timing data is not available (because multiple threads cannot open the same in-memory database).
To start hammerdb run the ./hammerdbws command on Linux or hammerdbws.bat on Windows.
./hammerdbws
Navigating to the defined port will show the Web Service interface, and clicking on the API link will return the available commands.
HammerDB Web Service Interface
In addition to the HTTP interface, the web service interface also provides a CLI interface to the service. This CLI interface translates the existing CLI commands to call the HTTP API whilst translating the output to JSON format. At v4.3 the web service CLI supports all commands support by the standard CLI except for primary/replica features meaning switchmode and steprun are not available.
The web service CLI means that direct HTTP calls and CLI commands can be mixed whilst storing all output in the SQLite repository for querying at a later time.
Running a schema build
The following PostgreSQL build script will run in both the standard and web service CLI.
Running in the web service CLI we can see that the command output is returned to the user, however the virtual user output is no longer returned and instead a jobid is given.
./hammerdbws
HammerDB Web Service v4.3
Copyright (C) 2003-2021 Steve Shaw
Type "help" for a list of commands
The xml is well-formed, applying configuration
Initialized new SQLite on-disk database /tmp/hammer.DB
Starting HammerDB Web Service on port 8080
Listening for HTTP requests on TCP port 8080
hammerws>source pgbuild.tcl
{"success": {"message": "Database set to PostgreSQL"}}
{"success": {"message": "Benchmark set to TPC-C for PostgreSQL"}}
{"success": {"message": "Changed tpcc:pg_count_ware from 1 to 20 for PostgreSQL"}}
{"success": {"message": "Changed tpcc:pg_num_vu from 1 to 4 for PostgreSQL"}}
{"success": {"message": "Value postgres for tpcc:pg_superuserpass is the same as existing value postgres, no change made"}}
{"success": {"message": "Building 20 Warehouses with 5 Virtual Users, 4 active + 1 Monitor VU(dict value pg_num_vu is set to 4): JOBID=619CF6B05D1703E263931333"}}
The jobids can be queried directly over HTTP
List Jobs
and also for example the status of the current job.
Job status
This same output is available at the CLI prompt using the jobs command.
In this example, we use the HTTP interface to verify the output that the build completed successfully.
Build Job Complete
Running a Test
The following script is also recognisable as a valid CLI script with the addition of jobs commands to retrieve the test output.
dbset db pg
print dict
diset tpcc pg_superuser postgres
diset tpcc pg_defaultdbase postgres
diset tpcc pg_driver timed
diset tpcc pg_rampup 1
diset tpcc pg_duration 2
diset tpcc pg_timeprofile true
tcset refreshrate 10
loadscript
foreach z {1 2 4 8} {
puts "$z VU TEST"
vuset vu $z
vucreate
tcstart
set jobid [ vurun ]
runtimer 200
tcstop
jobs $jobid result
jobs $jobid timing
vudestroy
}
puts "JOB SEQUENCE ENDED"
Note that in this example using runtimer to automate the tests means that the interactive prompt will not return whilst the test is running, however it is still possible to query the jobs using the HTTP interface whilst running.
Job status
Running this test script returns the following output. Note that the job result and timing data is now queried from the SQLite repository during the script run.
With all jobs complete the SQLite repository can be queried either over HTTP or from the jobs command. If the webservice is stopped and restarted an on-disk repository is retained for querying at a later point in time.
The help jobs command can show the available commands to query the repository.
hammerws>help jobs
jobs - Usage: jobs
list all jobs.
jobs - Usage: jobs [jobid|result|timestamp]
jobid: list VU output for jobid.
result: list result for all jobs.
timestamp: list starting timestamp for all jobs.
jobs jobid - Usage: jobs jobid [bm|db|delete|dict|result|status|tcount|timestamp|timing|vuid]
bm: list benchmark for jobid.
db: list database for jobid.
delete: delete jobid.
dict: list dict for jobid.
result: list result for jobid.
status: list status for jobid.
tcount: list count for jobid.
timestamp: list starting timestamp for jobid.
timing: list xtprof summary timings for jobid.
vuid: list VU output for VU with vuid for jobid.
jobs jobid timing - Usage: jobs jobid timing vuid
timing vuid: list xtprof timings for vuid for jobid.
The CLI jobs result command will query all jobs and return the result if it finds one. In the example below as expected the build job does not have a result but the results are returned for all of the driver jobs.
hammerws>jobs result
[
"619CF6B05D1703E263931333",
"Jobid has no test result"
]
[
"619D05045D1703E213238373",
"2021-11-23 15:13:08",
"1 Active Virtual Users configured",
"TEST RESULT : System achieved 8089 NOPM from 18636 PostgreSQL TPM"
]
[
"619D05BC5D1703E263930313",
"2021-11-23 15:16:12",
"2 Active Virtual Users configured",
"TEST RESULT : System achieved 14102 NOPM from 32446 PostgreSQL TPM"
]
[
"619D06735D1703E263039373",
"2021-11-23 15:19:15",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 22392 NOPM from 51340 PostgreSQL TPM"
]
[
"619D072D5D1703E273631383",
"2021-11-23 15:22:21",
"8 Active Virtual Users configured",
"TEST RESULT : System achieved 36483 NOPM from 84065 PostgreSQL TPM"
]
An individual job can queried for any related information such as the timestamp when the job started, the configuration dict for the job or as the example below because the transaction counter was started the transaction count data for the run can retrieved based on the jobid.
It should be clear that the v4.3 Webservice functionality provides a building block to integrate HammerDB functionality into wider webservice environments. The addition of the CLI provides an easy to use command line interface to the functionality whilst the SQLite repository and output in JSON format enables HammerDB workloads to be automated with results, output, timing data and configuration all able to be retrieved for a particular job at any further point in time.
Introducing the PostgreSQL performance metrics viewer
Prior to version 4.3, HammerDB included a graphical performance metrics view for the Oracle database only. At v4.3 HammerDB includes the same functionality for PostgreSQL enabling the user to drill down on database metrics in real time. Additionally, using the Active Session History functionality, it is possible to select a previous time period of statistics in the graph and view the PostgreSQL metrics for this earlier period of time. This enables the user to compare and contrast performance across different benchmark scenarios.
PostgreSQL Graphical Metrics
Install pg_stat_statements and pg_sentinel extensions
To use the PostgreSQL graphical metrics, it is necessary to install the pg_stat_statements and pg_sentinel extensions first in the database to be viewed.
This example uses a PostgreSQL source based build with the pg_stat_statements extension found in the contrib directory. Running make and make install in this directory installs the extension.
With the pg_stat_statements and pg_sentinel extensions installed, it is now possible to start the HammerDB graphical metrics to view the Active Session History.
Under the tree view there is the Metrics entry enabling the editing of options and to start the display. Note that if a workload is running and the treeview is locked, it is also possible to access the options from the Options menu and to start the metrics from the Metrics button.
PostgreSQL Metrics treeview
Clicking on options, it shows the login credentials for the PostgreSQL superuser. The Agent ID and Hostname are identical to the metrics option at earlier HammerDB versions, enabling the viewing of CPU performance by connecting to a running agent.
PostgreSQL Metrics Options
By clicking on the Metrics Display option, HammerDB will connect to the target database and start monitoring the performance, note that if the pg_active_session_history table is empty the viewer will report an error and refuse to start.
No rows found
If the pg_active_session_history table is populated (after running or having previously run a workload) the Metrics tab will become activated.
Started Metrics
Viewing PostgreSQL Metrics for a HammerDB workload
For full performance details, grab the Metrics tab and pull it out of the HammerDB window to expand.
Drag out Metrics tab
The example shows a TPROC-C workload running with 4 Active Virtual Users. The example has a configuration set to illustrate a number of wait events and has therefore not been configured for performance.
Workload running
The PostgreSQL performance metrics will automatically start to be populated in the viewer. The options enable the user to drill down on the SQL running in the database, the wait events and the user statistics. The example shows we have 4 users called tpcc running the SQL from the TPROC-C workload with key WALWrite and CPU events. The events are colour coded and indexed in the graph to the wait event groups.
Metrics view for benchmark
When a benchmark workload has completed, use the selection tool in the graph to select the metrics for a period of time of interest. The viewer will be populated with the metrics for that specific period of time. Clicking on the SQL, events or user will display the output relevant to that selection. The SQL entry gives further options of sql text, io and stats, the wait events show the SQL that caused that wait event and the users show a summary of statistics for that user. The following example shows the SQL view.
Active Session History SQL view
The following example shows the LWLock WalWrite event, illustrating the top SQL that caused that event.
Active Session History event view
Closing the Window will return it to the main GUI showing the performance graph summary.
Summary display
Pressing stop on the Metrics button will close the PostgreSQL metrics viewer.
Summary
The HammerDB graphical metrics viewer in v4.3 adds the functionality to view the PostgreSQL active session history for benchmark workloads, enabling the user to find and diagnose bottlenecks in hardware and software configurations in a PostgreSQL environment. Further information on CPU and database metrics can be found in the documentation.