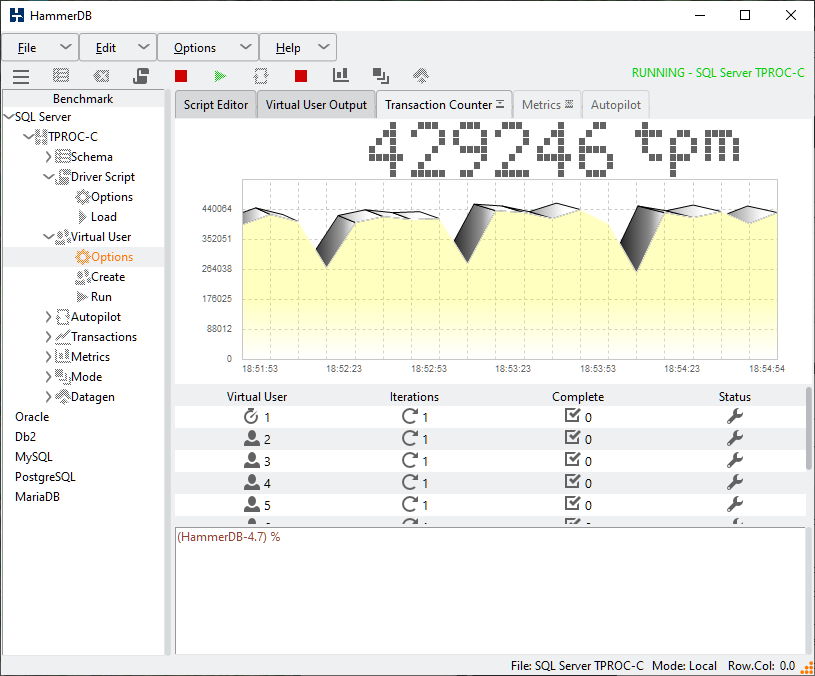
With the HammerDB v4.5 Docker build, example CLI scripts were added to build and run the TPROC-C workload in the Tcl language. In HammerDB v4.6 these were enhanced to also add Python based scripts, and to include scripts for both TPROC-C and TPROC-H and a driver script for Linux environments. With HammerDB v4.7 these scripts have now moved into the main HammerDB directory to be included with all installations, rather than Docker only and a powershell driver script also added for Windows. This post will give an overview of the example CLI scripts that you can run directly or use as a template to write your own.
When you list the HammerDB directory you can now see a directory called “scripts”. This directory contains CLI scripts to build, run, delete and query TPROC-C and TPROC-H workloads against all databases.
~/HammerDB-4.7$ ls -1
agent
bin
ChangeLog
CODE_OF_CONDUCT.md
config
hammerdb
hammerdbcli
hammerdbws
images
include
lib
LICENSE
modules
README.md
scripts
src
There is an option to run workloads in both Tcl and Python, note that these workloads underneath are identical, only the top-level interface is different and therefore there is no difference as to which language you use.
Linux example
For a first example we will look at the TPROC-C workload in Tcl running on MariaDB on Linux. In this directory you can see the generic build, run, delete and result query scripts as well as the Linux and Windows driver scripts.
~/HammerDB-4.7/scripts/tcl/maria/tprocc$ ls -1
maria_tprocc_buildschema.tcl
maria_tprocc_deleteschema.tcl
maria_tprocc.ps1
maria_tprocc_result.tcl
maria_tprocc_run.tcl
maria_tprocc.sh
in the driver script you can see that the TMP environment variable is set to the local directory and that the script is intended to be run from the main HammerDB directory and will call the build, run, delete and result scripts in turn.
export TMP=`pwd`/TMP
mkdir -p $TMP
echo "BUILD HAMMERDB SCHEMA"
echo "+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-"
./hammerdbcli auto ./scripts/tcl/maria/tprocc/maria_tprocc_buildschema.tcl
echo "+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-"
echo "RUN HAMMERDB TEST"
echo "+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-"
./hammerdbcli auto ./scripts/tcl/maria/tprocc/maria_tprocc_run.tcl
echo "+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-"
echo "DROP HAMMERDB SCHEMA"
./hammerdbcli auto ./scripts/tcl/maria/tprocc/maria_tprocc_deleteschema.tcl
echo "+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-"
echo "HAMMERDB RESULT"
./hammerdbcli auto ./scripts/tcl/maria/tprocc/maria_tprocc_result.tcl
First of all you should check the connection properties in your scripts and modify them to connect to your database. Note that by default the build script will query the number of CPUs on the system that HammerDB is running and configure 5X this number for the number of warehouses to build. If this value is greater or equal to 200 it will also partition the schema. If HammerDB is running on a separate system from the database under test then you should modify this value accordingly.
puts "SETTING CONFIGURATION"
dbset db maria
dbset bm TPC-C
diset connection maria_host localhost
diset connection maria_port 3306
diset connection maria_socket /tmp/mariadb.sock
set vu [ numberOfCPUs ]
set warehouse [ expr {$vu * 5} ]
diset tpcc maria_count_ware $warehouse
diset tpcc maria_num_vu $vu
diset tpcc maria_user root
diset tpcc maria_pass maria
diset tpcc maria_dbase tpcc
diset tpcc maria_storage_engine innodb
if { $warehouse >= 200 } {
diset tpcc maria_partition true
} else {
diset tpcc maria_partition false
}
puts "SCHEMA BUILD STARTED"
buildschema
puts "SCHEMA BUILD COMPLETED"
For the run script, it will run a timed test with the use all warehouses setting enabled as well as the transaction counter and time profiling running. It will create the number of virtual users to the number of CPUs on the system where HammerDB is running.
set tmpdir $::env(TMP)
puts "SETTING CONFIGURATION"
dbset db maria
dbset bm TPC-C
diset connection maria_host localhost
diset connection maria_port 3306
diset connection maria_socket /tmp/mariadb.sock
diset tpcc maria_user root
diset tpcc maria_pass maria
diset tpcc maria_dbase tpcc
diset tpcc maria_driver timed
diset tpcc maria_rampup 2
diset tpcc maria_duration 5
diset tpcc maria_allwarehouse true
diset tpcc maria_timeprofile true
loadscript
puts "TEST STARTED"
vuset vu vcpu
vucreate
tcstart
tcstatus
set jobid [ vurun ]
vudestroy
tcstop
puts "TEST COMPLETE"
set of [ open $tmpdir/maria_tprocc w ]
puts $of $jobid
close $of
Once the workload has run, the delete script will delete the schema previously configured.
puts "SETTING CONFIGURATION"
dbset db maria
dbset bm TPC-C
diset connection maria_host localhost
diset connection maria_port 3306
diset connection maria_socket /tmp/mariadb.sock
diset tpcc maria_user root
diset tpcc maria_pass maria
diset tpcc maria_dbase tpcc
puts " DROP SCHEMA STARTED"
deleteschema
puts "DROP SCHEMA COMPLETED"
and finally the result script will report the results from the test.
set tmpdir $::env(TMP)
set ::outputfile $tmpdir/maria_tprocc
source ./scripts/tcl/generic/generic_tprocc_result.tcl
If we run the driver script, we see the following output (with build output truncated). Note that the NOPM/TPM result, transaction times, response times are reported at the end of the file.
$ ./scripts/tcl/maria/tprocc/maria_tprocc.sh
BUILD HAMMERDB SCHEMA
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.7/TMP/hammer.DB using existing tables (188,416 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
....
ALL VIRTUAL USERS COMPLETE
SCHEMA BUILD COMPLETED
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
RUN HAMMERDB TEST
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.7/TMP/hammer.DB using existing tables (180,224 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
Value localhost for connection:maria_host is the same as existing value localhost, no change made
Value 3306 for connection:maria_port is the same as existing value 3306, no change made
Value /tmp/mariadb.sock for connection:maria_socket is the same as existing value /tmp/mariadb.sock, no change made
Value root for tpcc:maria_user is the same as existing value root, no change made
Value maria for tpcc:maria_pass is the same as existing value maria, no change made
Value tpcc for tpcc:maria_dbase is the same as existing value tpcc, no change made
Value timed for tpcc:maria_driver is the same as existing value timed, no change made
Value 2 for tpcc:maria_rampup is the same as existing value 2, no change made
Value 5 for tpcc:maria_duration is the same as existing value 5, no change made
Changed tpcc:maria_allwarehouse from false to true for MariaDB
Changed tpcc:maria_timeprofile from false to true for MariaDB
Script loaded, Type "print script" to view
TEST STARTED
Vuser 1 created MONITOR - WAIT IDLE
Vuser 2 created - WAIT IDLE
Vuser 3 created - WAIT IDLE
Vuser 4 created - WAIT IDLE
Vuser 5 created - WAIT IDLE
5 Virtual Users Created with Monitor VU
Transaction Counter Started
Transaction Counter thread running with threadid:tid0x7f554ffff700
Vuser 1:RUNNING
Vuser 1:Initializing xtprof time profiler
Vuser 1:Ssl_cipher
Vuser 1:Beginning rampup time of 2 minutes
0 MariaDB tpm
Vuser 2:RUNNING
Vuser 2:Initializing xtprof time profiler
Vuser 2:Ssl_cipher
Vuser 2:VU 2 : Assigning WID=1 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 2:VU 2 : Assigning WID=5 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 2:VU 2 : Assigning WID=9 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 2:VU 2 : Assigning WID=13 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 2:VU 2 : Assigning WID=17 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 2:Processing 10000000 transactions with output suppressed...
Vuser 3:RUNNING
Vuser 3:Initializing xtprof time profiler
Vuser 3:Ssl_cipher
Vuser 3:VU 3 : Assigning WID=2 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 3:VU 3 : Assigning WID=6 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 3:VU 3 : Assigning WID=10 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 3:VU 3 : Assigning WID=14 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 3:VU 3 : Assigning WID=18 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 3:Processing 10000000 transactions with output suppressed...
Vuser 4:RUNNING
Vuser 4:Initializing xtprof time profiler
Vuser 4:Ssl_cipher
Vuser 4:VU 4 : Assigning WID=3 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 4:VU 4 : Assigning WID=7 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 4:VU 4 : Assigning WID=11 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 4:VU 4 : Assigning WID=15 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 4:VU 4 : Assigning WID=19 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 4:Processing 10000000 transactions with output suppressed...
Vuser 5:RUNNING
Vuser 5:Initializing xtprof time profiler
Vuser 5:Ssl_cipher
Vuser 5:VU 5 : Assigning WID=4 based on VU count 4, Warehouses = 20 (1 out of 5)
Vuser 5:VU 5 : Assigning WID=8 based on VU count 4, Warehouses = 20 (2 out of 5)
Vuser 5:VU 5 : Assigning WID=12 based on VU count 4, Warehouses = 20 (3 out of 5)
Vuser 5:VU 5 : Assigning WID=16 based on VU count 4, Warehouses = 20 (4 out of 5)
Vuser 5:VU 5 : Assigning WID=20 based on VU count 4, Warehouses = 20 (5 out of 5)
Vuser 5:Processing 10000000 transactions with output suppressed...
77694 MariaDB tpm
90450 MariaDB tpm
81822 MariaDB tpm
79800 MariaDB tpm
82176 MariaDB tpm
Vuser 1:Rampup 1 minutes complete ...
81834 MariaDB tpm
81972 MariaDB tpm
81648 MariaDB tpm
81798 MariaDB tpm
81438 MariaDB tpm
80508 MariaDB tpm
Vuser 1:Rampup 2 minutes complete ...
Vuser 1:Rampup complete, Taking start Transaction Count.
Vuser 1:Timing test period of 5 in minutes
79194 MariaDB tpm
80826 MariaDB tpm
79920 MariaDB tpm
86010 MariaDB tpm
62040 MariaDB tpm
52104 MariaDB tpm
Vuser 1:1 ...,
56982 MariaDB tpm
62982 MariaDB tpm
62124 MariaDB tpm
66990 MariaDB tpm
65562 MariaDB tpm
58662 MariaDB tpm
Vuser 1:2 ...,
58428 MariaDB tpm
64380 MariaDB tpm
63972 MariaDB tpm
64146 MariaDB tpm
66588 MariaDB tpm
64188 MariaDB tpm
Vuser 1:3 ...,
65622 MariaDB tpm
66576 MariaDB tpm
64860 MariaDB tpm
68784 MariaDB tpm
70176 MariaDB tpm
69798 MariaDB tpm
Vuser 1:4 ...,
67494 MariaDB tpm
70884 MariaDB tpm
70260 MariaDB tpm
68388 MariaDB tpm
68922 MariaDB tpm
67584 MariaDB tpm
Vuser 1:5 ...,
Vuser 1:Test complete, Taking end Transaction Count.
Vuser 1:4 Active Virtual Users configured
Vuser 1:TEST RESULT : System achieved 28639 NOPM from 66769 MariaDB TPM
Vuser 1:Gathering timing data from Active Virtual Users...
68418 MariaDB tpm
Vuser 2:FINISHED SUCCESS
Vuser 4:FINISHED SUCCESS
Vuser 5:FINISHED SUCCESS
Vuser 3:FINISHED SUCCESS
Vuser 1:Calculating timings...
Vuser 1:Writing timing data to /home/steve/HammerDB-4.7/TMP/hdbxtprofile.log
Vuser 1:FINISHED SUCCESS
ALL VIRTUAL USERS COMPLETE
vudestroy success
Transaction Counter thread running with threadid:tid0x7f554ffff700
Stopping Transaction Counter
TEST COMPLETE
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
DROP HAMMERDB SCHEMA
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.7/TMP/hammer.DB using existing tables (188,416 KB)
SETTING CONFIGURATION
Database set to MariaDB
Benchmark set to TPC-C for MariaDB
Value localhost for connection:maria_host is the same as existing value localhost, no change made
Value 3306 for connection:maria_port is the same as existing value 3306, no change made
Value /tmp/mariadb.sock for connection:maria_socket is the same as existing value /tmp/mariadb.sock, no change made
Value root for tpcc:maria_user is the same as existing value root, no change made
Value maria for tpcc:maria_pass is the same as existing value maria, no change made
Value tpcc for tpcc:maria_dbase is the same as existing value tpcc, no change made
DROP SCHEMA STARTED
Script cleared
Deleting schema with 1 Virtual User
Do you want to delete the TPCC TPROC-C schema
in host LOCALHOST:/TMP/MARIADB.SOCK under user ROOT?
Enter yes or no: replied yes
Vuser 1 created - WAIT IDLE
Vuser 1:RUNNING
Vuser 1:Ssl_cipher
DROP SCHEMA COMPLETED
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
HAMMERDB RESULT
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.7/TMP/hammer.DB using existing tables (188,416 KB)
TRANSACTION RESPONSE TIMES
{
"NEWORD": {
"elapsed_ms": "419814.0",
"calls": "54189",
"min_ms": "1.35",
"avg_ms": "4.197",
"max_ms": "191.359",
"total_ms": "227425.383",
"p99_ms": "14.25",
"p95_ms": "6.883",
"p50_ms": "3.788",
"sd": "3363.096",
"ratio_pct": "54.162"
},
"PAYMENT": {
"elapsed_ms": "419814.0",
"calls": "54597",
"min_ms": "0.655",
"avg_ms": "1.647",
"max_ms": "121.584",
"total_ms": "89933.834",
"p99_ms": "6.288",
"p95_ms": "2.984",
"p50_ms": "1.424",
"sd": "1521.734",
"ratio_pct": "21.418"
},
"DELIVERY": {
"elapsed_ms": "419814.0",
"calls": "5389",
"min_ms": "4.782",
"avg_ms": "13.291",
"max_ms": "225.309",
"total_ms": "71627.506",
"p99_ms": "91.928",
"p95_ms": "27.917",
"p50_ms": "9.796",
"sd": "14775.748",
"ratio_pct": "17.058"
},
"OSTAT": {
"elapsed_ms": "419814.0",
"calls": "5386",
"min_ms": "0.488",
"avg_ms": "2.335",
"max_ms": "139.762",
"total_ms": "12574.798",
"p99_ms": "40.093",
"p95_ms": "4.248",
"p50_ms": "1.153",
"sd": "7285.123",
"ratio_pct": "2.995"
},
"SLEV": {
"elapsed_ms": "419814.0",
"calls": "5367",
"min_ms": "0.904",
"avg_ms": "1.949",
"max_ms": "93.56",
"total_ms": "10459.164",
"p99_ms": "6.379",
"p95_ms": "3.1",
"p50_ms": "1.698",
"sd": "1775.819",
"ratio_pct": "2.491"
}
}
TRANSACTION COUNT
{"MariaDB tpm": {
"0": "2023-03-24 14:35:24",
"77694": "2023-03-24 14:35:34",
"90450": "2023-03-24 14:35:44",
"81822": "2023-03-24 14:35:54",
"79800": "2023-03-24 14:36:04",
"82176": "2023-03-24 14:36:14",
"81834": "2023-03-24 14:36:24",
"81972": "2023-03-24 14:36:34",
"81648": "2023-03-24 14:36:44",
"81798": "2023-03-24 14:36:54",
"81438": "2023-03-24 14:37:04",
"80508": "2023-03-24 14:37:14",
"79194": "2023-03-24 14:37:24",
"80826": "2023-03-24 14:37:34",
"79920": "2023-03-24 14:37:44",
"86010": "2023-03-24 14:37:54",
"62040": "2023-03-24 14:38:04",
"52104": "2023-03-24 14:38:14",
"56982": "2023-03-24 14:38:24",
"62982": "2023-03-24 14:38:34",
"62124": "2023-03-24 14:38:44",
"66990": "2023-03-24 14:38:54",
"65562": "2023-03-24 14:39:04",
"58662": "2023-03-24 14:39:14",
"58428": "2023-03-24 14:39:24",
"64380": "2023-03-24 14:39:34",
"63972": "2023-03-24 14:39:44",
"64146": "2023-03-24 14:39:54",
"66588": "2023-03-24 14:40:04",
"64188": "2023-03-24 14:40:14",
"65622": "2023-03-24 14:40:24",
"66576": "2023-03-24 14:40:34",
"64860": "2023-03-24 14:40:44",
"68784": "2023-03-24 14:40:54",
"70176": "2023-03-24 14:41:04",
"69798": "2023-03-24 14:41:14",
"67494": "2023-03-24 14:41:24",
"70884": "2023-03-24 14:41:34",
"70260": "2023-03-24 14:41:44",
"68388": "2023-03-24 14:41:54",
"68922": "2023-03-24 14:42:04",
"67584": "2023-03-24 14:42:14",
"68418": "2023-03-24 14:42:24"
}}
HAMMERDB RESULT
[
"641DB52C5F7A03E213335373",
"2023-03-24 14:35:24",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 28639 NOPM from 66769 MariaDB TPM"
]
~/HammerDB-4.7/TMP$ more maria_tprocc_641DB52C5F7A03E213335373.out
TRANSACTION RESPONSE TIMES
{
"NEWORD": {
"elapsed_ms": "419814.0",
"calls": "54189",
"min_ms": "1.35",
"avg_ms": "4.197",
"max_ms": "191.359",
"total_ms": "227425.383",
"p99_ms": "14.25",
"p95_ms": "6.883",
"p50_ms": "3.788",
"sd": "3363.096",
"ratio_pct": "54.162"
},
"PAYMENT": {
"elapsed_ms": "419814.0",
"calls": "54597",
"min_ms": "0.655",
"avg_ms": "1.647",
"max_ms": "121.584",
"total_ms": "89933.834",
"p99_ms": "6.288",
"p95_ms": "2.984",
"p50_ms": "1.424",
"sd": "1521.734",
"ratio_pct": "21.418"
},
"DELIVERY": {
"elapsed_ms": "419814.0",
"calls": "5389",
"min_ms": "4.782",
"avg_ms": "13.291",
"max_ms": "225.309",
"total_ms": "71627.506",
"p99_ms": "91.928",
"p95_ms": "27.917",
"p50_ms": "9.796",
"sd": "14775.748",
"ratio_pct": "17.058"
},
"OSTAT": {
"elapsed_ms": "419814.0",
"calls": "5386",
"min_ms": "0.488",
"avg_ms": "2.335",
"max_ms": "139.762",
"total_ms": "12574.798",
"p99_ms": "40.093",
"p95_ms": "4.248",
"p50_ms": "1.153",
"sd": "7285.123",
"ratio_pct": "2.995"
},
"SLEV": {
"elapsed_ms": "419814.0",
"calls": "5367",
"min_ms": "0.904",
"avg_ms": "1.949",
"max_ms": "93.56",
"total_ms": "10459.164",
"p99_ms": "6.379",
"p95_ms": "3.1",
"p50_ms": "1.698",
"sd": "1775.819",
"ratio_pct": "2.491"
}
}
TRANSACTION COUNT
{"MariaDB tpm": {
"0": "2023-03-24 14:35:24",
"77694": "2023-03-24 14:35:34",
"90450": "2023-03-24 14:35:44",
"81822": "2023-03-24 14:35:54",
"79800": "2023-03-24 14:36:04",
"82176": "2023-03-24 14:36:14",
"81834": "2023-03-24 14:36:24",
"81972": "2023-03-24 14:36:34",
"81648": "2023-03-24 14:36:44",
"81798": "2023-03-24 14:36:54",
"81438": "2023-03-24 14:37:04",
"80508": "2023-03-24 14:37:14",
"79194": "2023-03-24 14:37:24",
"80826": "2023-03-24 14:37:34",
"79920": "2023-03-24 14:37:44",
"86010": "2023-03-24 14:37:54",
"62040": "2023-03-24 14:38:04",
"52104": "2023-03-24 14:38:14",
"56982": "2023-03-24 14:38:24",
"62982": "2023-03-24 14:38:34",
"62124": "2023-03-24 14:38:44",
"66990": "2023-03-24 14:38:54",
"65562": "2023-03-24 14:39:04",
"58662": "2023-03-24 14:39:14",
"58428": "2023-03-24 14:39:24",
"64380": "2023-03-24 14:39:34",
"63972": "2023-03-24 14:39:44",
"64146": "2023-03-24 14:39:54",
"66588": "2023-03-24 14:40:04",
"64188": "2023-03-24 14:40:14",
"65622": "2023-03-24 14:40:24",
"66576": "2023-03-24 14:40:34",
"64860": "2023-03-24 14:40:44",
"68784": "2023-03-24 14:40:54",
"70176": "2023-03-24 14:41:04",
"69798": "2023-03-24 14:41:14",
"67494": "2023-03-24 14:41:24",
"70884": "2023-03-24 14:41:34",
"70260": "2023-03-24 14:41:44",
"68388": "2023-03-24 14:41:54",
"68922": "2023-03-24 14:42:04",
"67584": "2023-03-24 14:42:14",
"68418": "2023-03-24 14:42:24"
}}
HAMMERDB RESULT
[
"641DB52C5F7A03E213335373",
"2023-03-24 14:35:24",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 28639 NOPM from 66769 MariaDB TPM"
]
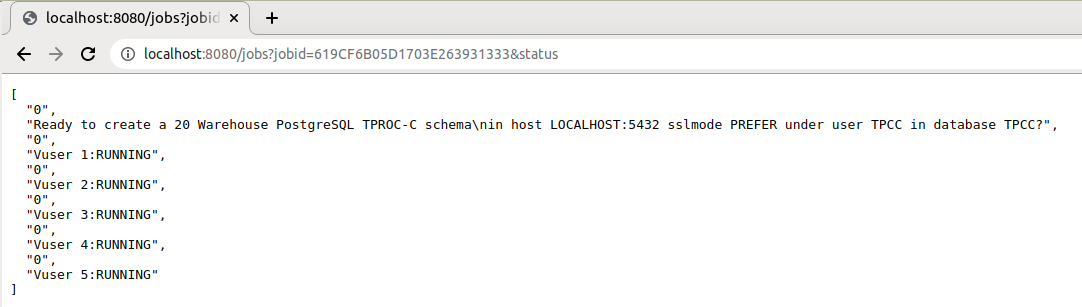
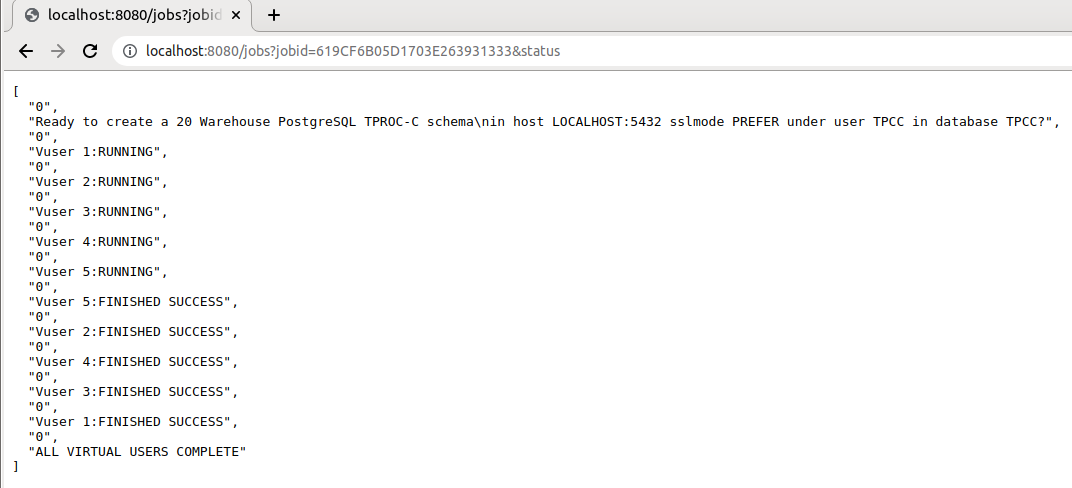
Note that the jobs are stored in the SQLite database in the configured TMP directory and therefore this can be queried with the jobs command to view all of the data stored for the job such as the dict and the response times for all running virtual users.
$ export TMP=`pwd`/TMP
$ ./hammerdbcli
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help" for a list of commands
Initialized SQLite on-disk database /home/steve/HammerDB-4.7/TMP/hammer.DB using existing tables (188,416 KB)
hammerdb>jobs result
[
"641DB40C5F7A03E273636303",
"Jobid has no test result"
]
[
"641DB52C5F7A03E213335373",
"2023-03-24 14:35:24",
"4 Active Virtual Users configured",
"TEST RESULT : System achieved 28639 NOPM from 66769 MariaDB TPM"
]
Windows example
For a Windows example we will look at the Python scripts for TPROC-H running against SQL Server.

Similarly to Linux, set the connection settings in all scripts. To edit the scripts within the Program Files directory run an editor such as Notepad as administrator.
#!/bin/tclsh
# maintainer: Pooja Jain
print("SETTING CONFIGURATION")
dbset('db','mssqls')
dbset('bm','TPC-H')
diset('connection','mssqls_tcp','false')
diset('connection','mssqls_port','1433')
diset('connection','mssqls_azure','false')
diset('connection','mssqls_encrypt_connection','true')
diset('connection','mssqls_trust_server_cert','true')
diset('connection','mssqls_authentication','windows')
diset('connection','mssqls_server','{(local)\SQLDEVELOP}')
diset('connection','mssqls_linux_server','{localhost}')
diset('connection','mssqls_linux_authent','sql')
diset('connection','mssqls_linux_odbc','{ODBC Driver 18 for SQL Server}')
diset('connection','mssqls_uid','sa')
diset('connection','mssqls_pass','admin')
vu = tclpy.eval('numberOfCPUs')
diset('tpch','mssqls_num_tpch_threads',vu)
diset('tpch','mssqls_scale_fact','1')
diset('tpch','mssqls_maxdop','2')
diset('tpch','mssqls_tpch_dbase','tpch')
diset('tpch','mssqls_colstore','false')
print("SCHEMA BUILD STARTED")
buildschema()
print("SCHEMA BUILD COMPLETED")
exit()
Note that by default running powershell scripts is disabled and therefore to run the HammerDB scripts on Windows this functionality should be enabled as follows.
To run the workload, call the powershell script from the HammerDB home directory.
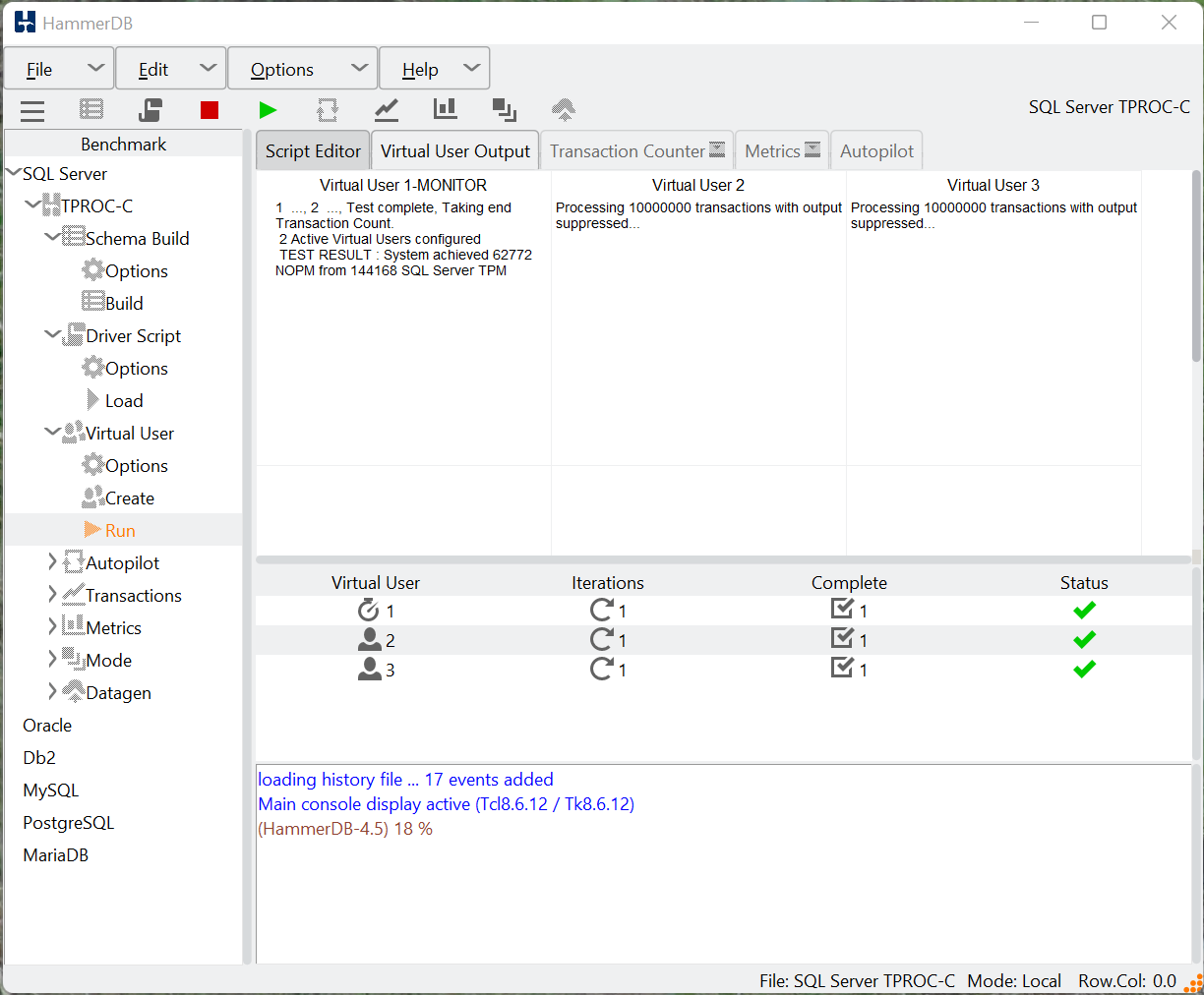
C:\Program Files\HammerDB-4.7>powershell .\scripts\python\mssqls\tproch\mssqls_tproch_py.ps1
As on Linux, the workload will build, run, delete and report the results of the workload.
HAMMERDB RESULT
HammerDB CLI v4.7
Copyright (C) 2003-2023 Steve Shaw
Type "help()" for a list of commands
HAMMERDB RESULT
[
"1",
"Executing Query 14 (1 of 22)",
"1",
"query 14 completed in 0.136 seconds",
"1",
"Executing Query 2 (2 of 22)",
"1",
"query 2 completed in 0.229 seconds",
"1",
"Executing Query 9 (3 of 22)",
"1",
"query 9 completed in 1.206 seconds",
"1",
"Executing Query 20 (4 of 22)",
"1",
"query 20 completed in 0.195 seconds",
"1",
"Executing Query 6 (5 of 22)",
"1",
"query 6 completed in 0.283 seconds",
"1",
"Executing Query 17 (6 of 22)",
"1",
"query 17 completed in 0.191 seconds",
"1",
"Executing Query 18 (7 of 22)",
"1",
"query 18 completed in 0.601 seconds",
"1",
"Executing Query 8 (8 of 22)",
"1",
"query 8 completed in 0.693 seconds",
"1",
"Executing Query 21 (9 of 22)",
"1",
"query 21 completed in 1.045 seconds",
"1",
"Executing Query 13 (10 of 22)",
"1",
"query 13 completed in 2.973 seconds",
"1",
"Executing Query 3 (11 of 22)",
"1",
"query 3 completed in 0.279 seconds",
"1",
"Executing Query 22 (12 of 22)",
"1",
"query 22 completed in 0.276 seconds",
"1",
"Executing Query 16 (13 of 22)",
"1",
"query 16 completed in 0.383 seconds",
"1",
"Executing Query 4 (14 of 22)",
"1",
"query 4 completed in 0.33 seconds",
"1",
"Executing Query 11 (15 of 22)",
"1",
"query 11 completed in 0.094 seconds",
"1",
"Executing Query 15 (16 of 22)",
"1",
"query 15 completed in 0.18 seconds",
"1",
"Executing Query 1 (17 of 22)",
"1",
"query 1 completed in 0.997 seconds",
"1",
"Executing Query 10 (18 of 22)",
"1",
"query 10 completed in 0.356 seconds",
"1",
"Executing Query 19 (19 of 22)",
"1",
"query 19 completed in 0.516 seconds",
"1",
"Executing Query 5 (20 of 22)",
"1",
"query 5 completed in 0.408 seconds",
"1",
"Executing Query 7 (21 of 22)",
"1",
"query 7 completed in 0.263 seconds",
"1",
"Executing Query 12 (22 of 22)",
"1",
"query 12 completed in 0.403 seconds",
"1",
"Completed 1 query set(s) in 12 seconds",
"1",
"Geometric mean of query times returning rows (22) is \"0.38278\""
]
The temp directory used is the same default temp directory on Windows and therefore the output file can be found in this location.
![]()
Summary
The example scripts and driver scripts are intended as templates to show what you can do with your own HammerDB environment to build, run and delete workloads and query the results and configuration.