More than ever, we see confusion in interpreting and comparing the performance of databases with workloads derived from the TPC-Council’s TPC-C specification, including HammerDB’s TPROC-C NOPM and TPM.
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024.
tpmC
tpmC is the transactions per minute metric that is the measurement of the official TPC-C benchmark from the TPC-Council. To be more specific, tpmC measures the rate of New Order transactions only, executed per minute, while the database is also processing other transactions. Therefore, the tpmC is not the same as the number of total database transactions (i.e. transactions commits and rollbacks) recorded from the database metrics. This is an important concept, as different database engines may produce better performance with different ratios between tpmC and database transactions. Put simply, some database engines may perform better committing more frequently and some less so. Therefore, tpmC is the official metric and this is not the same as measuring database transactions.
Importantly, TPC-C and tpmC are registered trademarks of the TPC-Council. Without exception, TPC-C and tpmC can only be used for official audited TPC-C benchmarks published here by the TPC-Council. If a benchmark claiming a tpmC metric has not been audited and approved by the TPC-Council, then it is invalid as well as violating the registered trademarks of the TPC-C, only benchmarks found at the TPC-Council can use TPC-C and tpmC.
The TPC provide the specification for the TPC-C benchmark for free and workloads can be implemented derived from the specification, however it is not permitted to use the official terminology unless audited and HammerDB does not use the TPC-C and tpmC terminology to respect the TPC’s trademark.
NOPM and TPM/TPS
HammerDB implements a workload derived from the TPC-C specification called TPROC-C. HammerDB reports two metrics, NOPM and TPM. The easiest way to understand NOPM and TPM is to think of the two metrics as the same you see on a dashboard. NOPM is how fast you are going, i.e. throughput, and TPM is how hard the engine is working to deliver that throughput.
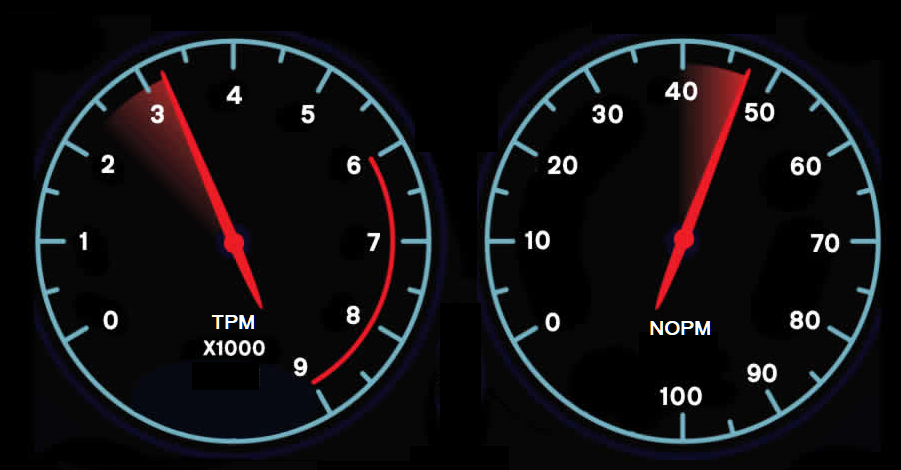
The two metrics are relative, however, they are not the same.
NOPM
The HammerDB NOPM metric measures the rate of New Order transactions only, executed per minute, while the database is also processing other transactions. It therefore measures and reports the same metric as the official tpmC, however we are permitted to use tpmC for the reasons given in the section above. The NOPM value is the key measure of workload throughput.
TPM (TPS)
TPM is the metric derived from the database engine of the number of commits and rollbacks it is processing. This metric will relate to the transaction counter of database tools, for example Batches/sec in activity monitor for SQL Server Management studio. This metric allows you to relate database performance to the performance analysis of a specific database engine, however should not be compared between database engines. Where you see a similar TPS metric, simply multiply by 60 for a TPM equivalent. Note that we should typically expect TPM to be at least double that of NOPM and therefore be aware of comparing a TPM/TPS value from one workload with the NOPM value of another.
Fixed throughput workloads
Another concept to be familiar with, when comparing TPC-C derived workloads, is that of fixed throughput workloads and implementing keying and thinking time delays between transactions. When using tpmC for an officially audited benchmark, this must be a fixed throughput workload, where each individual database session adds throughput so that the workload scales as we add more warehouses and users (and is another very good technical as well as legal reason not to use tpmC incorrectly). This type of approach can be implemented with HammerDB with the asynchronous scaling option as described in this post.
However, with HammerDB at very early stages of development, it was identified that the performance ratio observed between systems was the same with both the HammerDB default workload without keying and thinking time as the official published TPC-C benchmarks with keying and thinking time.
Why this would be the case is straightforward. With an official TPC-C benchmarks there tends to be a TP Monitor or middleware between the clients and the server and therefore the clients are not connecting directly to the database. An official benchmark will not typically be implemented with thousands of connections to the database, instead the connections are managed by the middleware, as HammerDB does with asynchronous scaling where each Virtual User manages a much larger user defined number of connections. It is the middleware which maintains connections to the database, again typically in the low hundreds, that are driving high levels of throughput. This is why the default no key and think time approach produces similar scaling ratios to the official implementations.
Response Times
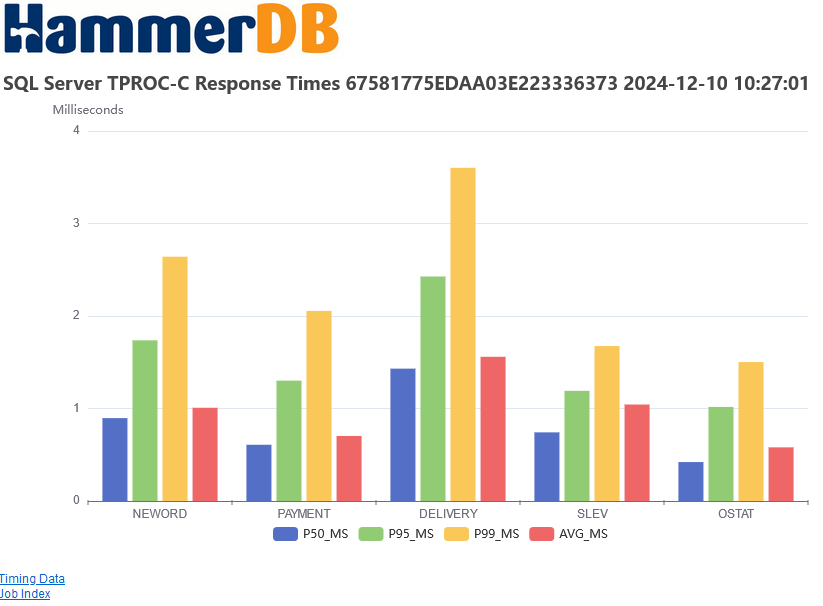
With HammerDB if you select the time profile checkbox it will record the response times of all the transactions. As shown below, using the HammerDB web service to view the results. NEWORD is transaction that we are measuring for the NOPM metric.
Clearly, there is a relationship between response times and throughput. For example, if we increase the number of virtual users and see performance at or lower than we saw at a lower number of virtual users, then the response times will be higher. For a ‘good’ level of throughput as we shall discuss in the next section our response should be in the low single-digit or tens of milliseconds. We should not expect response times to be in the region of hundreds or thousands of milliseconds (i.e. seconds).
What is ‘good’ performance?
Firstly, it is worth noting that database performance is relative. With a high-performance database platform, you can do more with less to achieve the same results. However, there are trade-offs with, for example, uptime and reliability and for example a distributed database environment may provide lower performance results and higher response times but higher levels of availability.
Also, price/performance is an important, unless you have an unlimited budget you should always consider the Total Cost of Ownership (TCO) for a 3-year period of the system to gauge how much a particular level of performance will cost you.
Nevertheless, the key concept of database benchmarking is repeatability, if you set up exactly the same database configuration and run HammerDB against it, you should expect the same result. Any difference in performance can be attributed to the changes that you make. Therefore, even when your testing environment is delivering throughput that far exceeds your expected production database performance, a test system that delivers better performance in a HammerDB test will also have the potential to outperform one for your real-world applications.
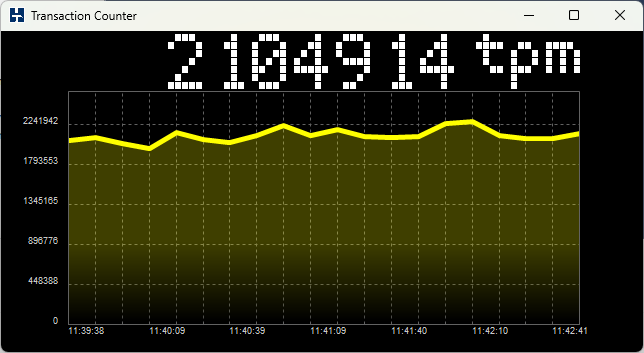
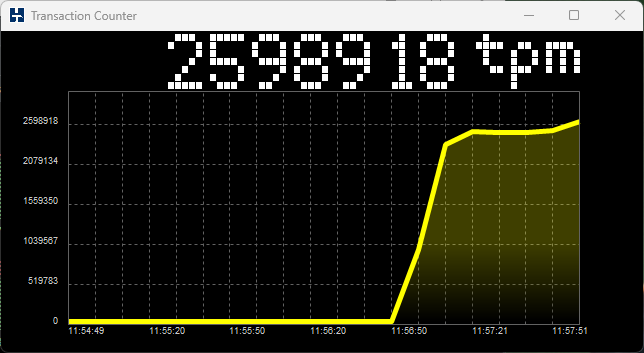
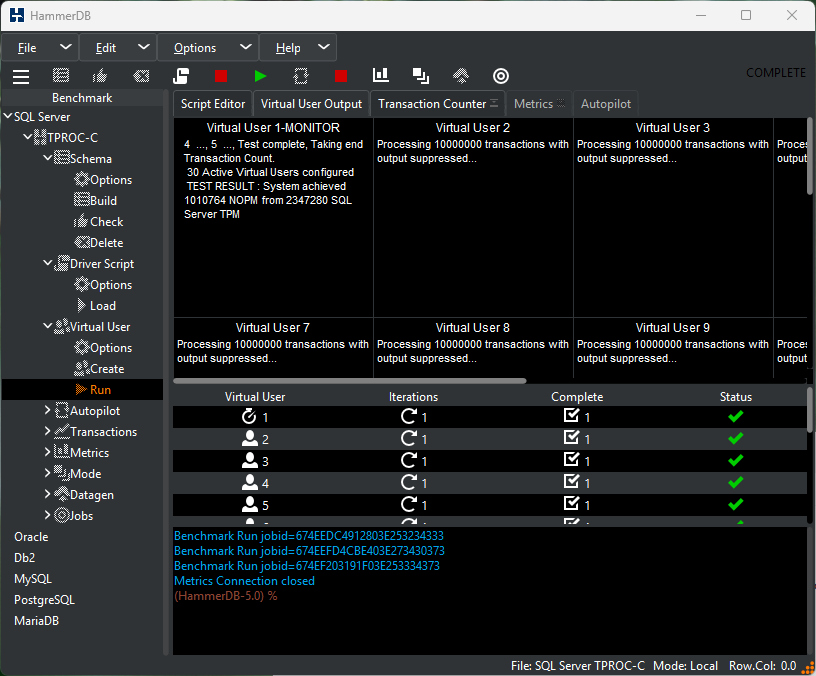
With these caveats, we can say that all the database engines that HammerDB supports can exceed 1M (1 million) NOPM for the HammerDB TPROC-C test, with the following example showing MariaDB.
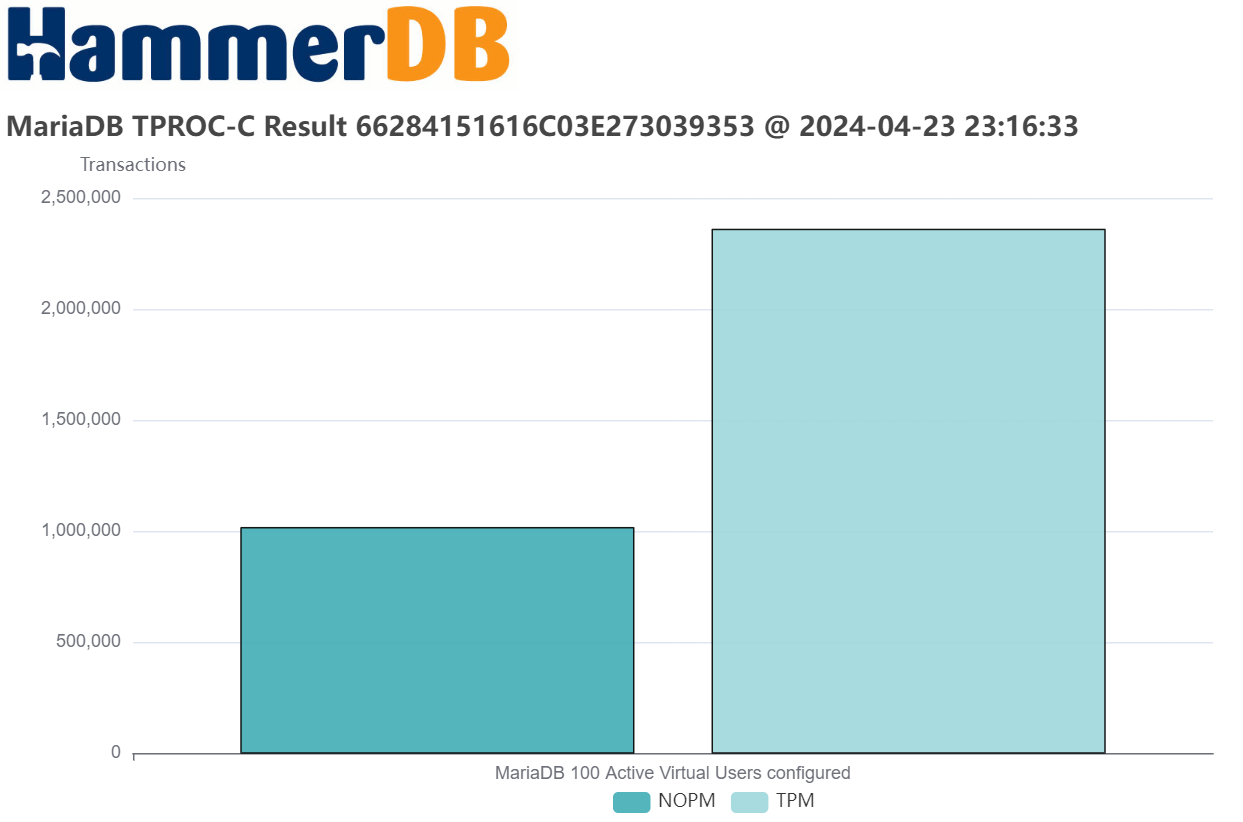
Also note as discussed that the database transaction rate exceeds 2M more than double the NOPM value as expected.
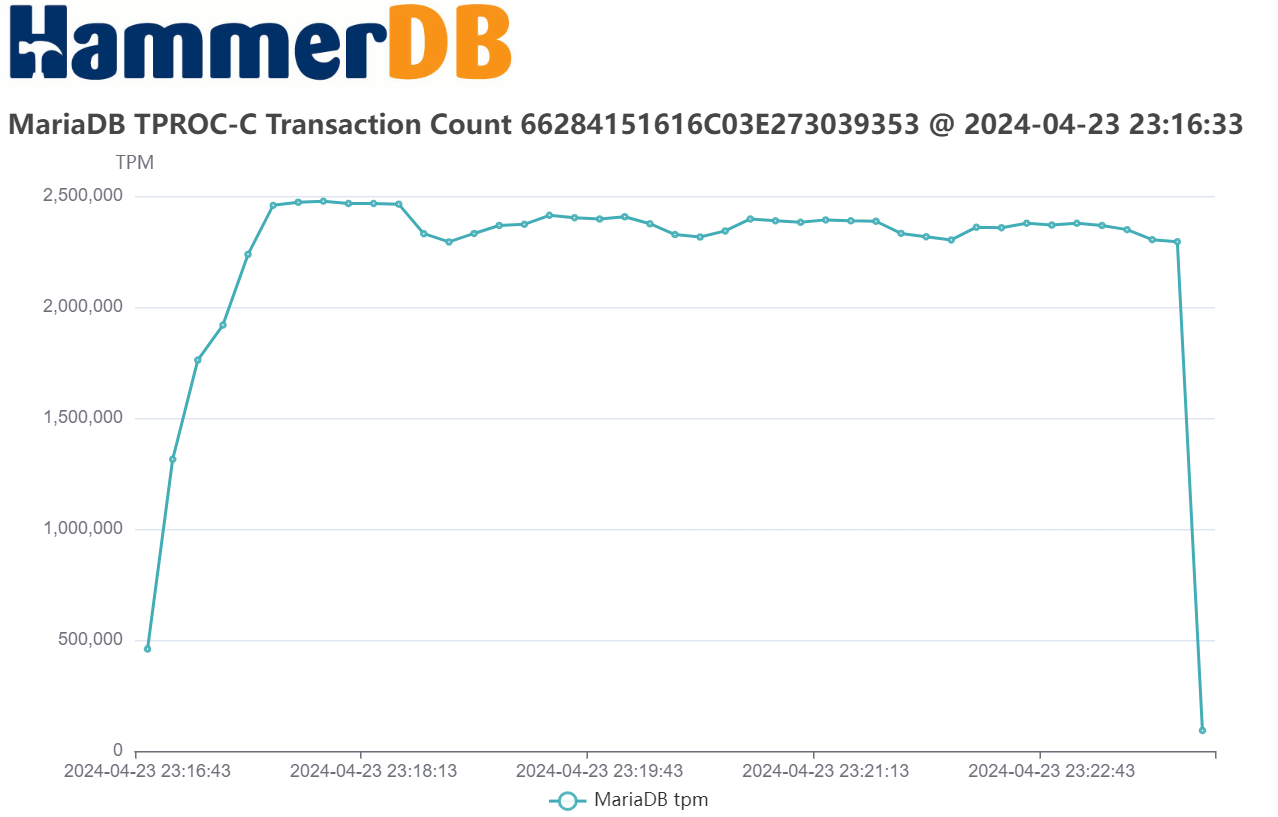
So, regardless of database engine, we have the potential to see HammerDB TPROC-C performance in the millions of NOPM and transactions. Of course, the exact figure that you see will depend on both hardware and software or more specifically for hardware – the CPU, memory, I/O and the ability of the engineer to configure and tune the hardware platform and for database software the ability of the engineer to configure and tune the database software and operating system (and virtualization layer), as well as to setup up run HammerDB. Results in the 10’s of millions are not uncommon with the most advanced hardware, software and expertise.
Summary
We have seen what metrics are important to a TPC-C derived test and how to interpret them. We have also seen what constitutes ‘good’ performance on an up-to-date system.
As a final point, it is worth noting that the commercial database supported by HammerDB have been running the TPC-C workload that HammerDB is derived from for a long-time and a comparatively large amount of time and effort went into ensuring these databases ran the TPC-C workload very well. Unsurprisingly, this translates directly into HammerDB performance, and with the right hardware and engineer expertise the commercial databases will both perform and scale well and set the bar as would be expected.
Additionally, open source database performance is improving rapidly all the time, and we have seen open source databases more than double performance in HammerDB tests in recent years compared to earlier releases. Always consider the latest releases when evaluating the potential of open source database performance. The ability to compare and contrast the performance of different database engines rather than running test workloads entirely in isolation that only run against one database is crucial to this improvement.
There has never been a more important time to be running your own database benchmarks to continually evaluate the optimal database platform for your needs.